초록
Grapheme-to-Phoneme (G2P)은 현대의 고품질 Text-to-Speech (TTS) 시스템에서 필수적인 첫 단계입니다. 현재 대부분의 G2P 시스템은 전문가들이 신중하게 제작한 사전을 기반으로 하고 있습니다. 이는 두 가지 문제를 야기합니다.
첫째, 사전은 고정된 음소 집합, 보통 ARPABET 또는 IPA를 사용하여 생성되는데, 이는 모든 언어에 대해 음소를 표현하는 최적의 방법이 아닐 수 있습니다.
둘째, 이러한 전문가 사전을 제작하는 데 필요한 인력 시간이 매우 많습니다.
본 논문에서는 이러한 문제를 해결하기 위해 최근의 자가 지도 학습 발전을 이용하여 고정된 표현 대신 데이터 기반 음소 표현을 얻습니다. 우리는 잘 구축된 사전을 활용하는 강력한 기준선과 우리의 사전 없는 접근 방식을 비교합니다.
또한, 우리의 데이터 기반 사전 없는 방법이 사전 없는 언어 사전이나 음소 집합, 즉 언어학적 전문 지식 없이도 Mean Opinion Score (MOS) 측면에서 기존의 규칙 기반 또는 사전 기반 신경망 G2P만큼 잘 수행되거나 약간 더 잘 수행된다는 것을 보여줍니다.
색인어— Grapheme-to-Phoneme, 데이터 기반 G2P, Text-to-Speech, 사전 없는 TTS, 자가 지도 학습
1. 서론
Text-to-Speech(TTS) 합성은 수십 년간 광범위한 연구의 대상이 되어왔습니다 [1, 2]. 초기에는 기존의 음성 데이터베이스에서 파형을 조립하는 연결합성 모델이 개발되었습니다. 그 후, 통계적 접근법이 도입되어 텍스트에서 음성 특징을 생성하고, 이를 보코더에 입력하여 최종 출력을 생성하였습니다. 그러나 이러한 방법들은 생성된 음성의 부자연스러움과 발음 오류로 인해 만족스러운 결과를 얻지 못했습니다.
Grapheme-to-Phoneme(G2P) 모델은 현재의 TTS 엔진의 필수 구성 요소입니다 [3, 4]. 이 분야의 초기 연구는 규칙 기반 및 공동 시퀀스 모델을 사용하여 이루어졌습니다. 그러나 딥 러닝 방법이 부상하면서 RNN 및 최근에는 Transformer 기반 아키텍처가 G2P, 자동 음성 인식[5, 6, 7], 기계 번역, TTS 합성 [3, 4, 8, 9]과 같은 다양한 작업을 수행하는 데 사용되었습니다. G2P 변환은 본질적으로 시퀀스-투-시퀀스 모델링 작업이므로 Encoder-Decoder 아키텍처[10, 11]를 사용하여 G2P 변환에서 개선된 성과를 얻을 수 있었습니다 [3].
전통적인 G2P 모델 [12]은 일반적으로 대형 사전을 사용하여 가장 빈번한 단어들을 사전 검색하고, 사전에 없는 단어들의 발음을 생성하기 위해 수작업으로 만든 규칙을 사용합니다. 반면, 신경망 G2P [3]는 신경망 훈련 데이터를 위해 사전을 사용하고, 획득한 네트워크를 사용하여 발음을 예측합니다.
이러한 두 가지 방법은 현대 TTS 시스템 구축에 중요한 역할을 했지만, 외부 사전이 필요하다는 점에서 심각한 한계가 있습니다. 사전을 구축하는 것은 여러 언어 전문가가 제안하고 그 유효성을 검증해야 하므로 비용이 많이 들고 매우 번거로운 작업입니다.
최근에는 대규모 다국어 ByT5 G2P [13]를 구축하려는 노력이 있었습니다. 이는 T5 트랜스포머 기반의 인코더-디코더 아키텍처 [14]를 사용하고, 여러 언어의 스크립트를 처리하기 위해 UTF8 기반의 입력 토큰화를 사용합니다. 이는 인터넷에서 공개적으로 사용 가능한 사전을 사용하여 최대 100개의 언어를 다루며, 사전의 크기와 품질은 다양합니다. 모든 언어에 대한 고품질 사전을 확보하는 어려움과 제한된 데이터나 노이즈가 많은 데이터에 대한 G2P 모델의 정확도 감소는 이 논문에서 분명히 드러납니다.
본 논문에서는 사전이 필요 없는 새로운 G2P 모델 훈련 메커니즘을 제안합니다. 우리는 TTS를 사용 사례로 사용하여 우리의 G2P 모델의 효과를 보여줍니다. 먼저, 레이블이 없는 음성 데이터를 사용하여 HuBERT [15]를 세 번 반복하여 사전 훈련합니다. 사전 훈련된 HuBERT 모델이 준비되면, 레이블이 있는 음성 데이터를 입력하고 특정 트랜스포머 레이어를 사용하여 음성 특징을 추출하고, k-평균 클러스터링을 적용하여 프레임 단위의 음소 타겟을 얻습니다. 우리는 쌍을 이룬 음소 타겟과 레이블이 있는 음성 데이터를 사용하여 우리의 G2P 트랜스포머 모델을 훈련합니다. 그런 다음 훈련된 G2P를 사용하여 Tacotron 2 [1] 모델을 훈련합니다.
2. 신경망 Grapheme-to-Phoneme
2.1. G2P 아키텍처
Transformer 기반 Grapheme-to-Phoneme(G2P) 모델은 LSTM / 순환 인코더-디코더 모델 [3, 16, 17]보다 우수한 성능을 보이며, 병렬 학습 속도가 빨라져 훈련 시간이 크게 줄어드는 장점이 있습니다.
신경망 G2P 모델은 글자 시퀀스 X = (x1, x2, ..., xn)를 입력으로 받습니다. 그런 다음 잠재 공간에서 표현 L = (l1, l2, ..., ln)를 생성하고 이를 디코더에 전달합니다. 마지막으로, 디코더는 자동회귀 방식으로 해당 음소 시퀀스 Y = (y1, y2, ..., ym)를 예측합니다. 여기서 n과 m은 각각 입력 및 출력의 토큰 길이입니다.
2.2. Text-to-Speech 시스템
TTS 작업을 위해 우리의 G2P를 평가하기 위해, 우리는 Tacotron 2 [1]를 TTS 모델로 사용합니다.
원래 Tacotron 2는 텍스트를 사용하지만, 많은 연구 [18, 19]에서 음소를 사용하는 것이 더 우수한 결과를 낳는다는 것을 발견했습니다.
따라서 우리의 실험에서는 Tacotron 모델에 음소를 입력으로 사용합니다.
3. 음성 인식에서의 자가 지도학습습
wav2vec2.0 [20]과 같은 모델은 입력 오디오 신호를 양자화하고 마스킹한 후 대조적 손실을 사용하여 레이블이 없는 데이터로부터 학습합니다. 반면, HuBERT [15]와 같은 모델은 음향 단위 발견 단계를 마스킹된 예측 표현 학습 단계와 분리하여 보다 직접적인 예측 손실 계산을 가능하게 합니다. => HuBERT의 Hidden Unit을 Clustering 하여, Acoustic Unit 을 찾는 과정이 포함되어 있어, 음소를 찾는 작업에 적합하다고 판단!
우리는 섹션 4에서 우리의 G2P 모델을 훈련하기 위해 이러한 음향 단위를 사용합니다. HuBERT에서 이러한 음향 단위를 얻기 위한 사전 훈련 접근법을 아래에 설명합니다.
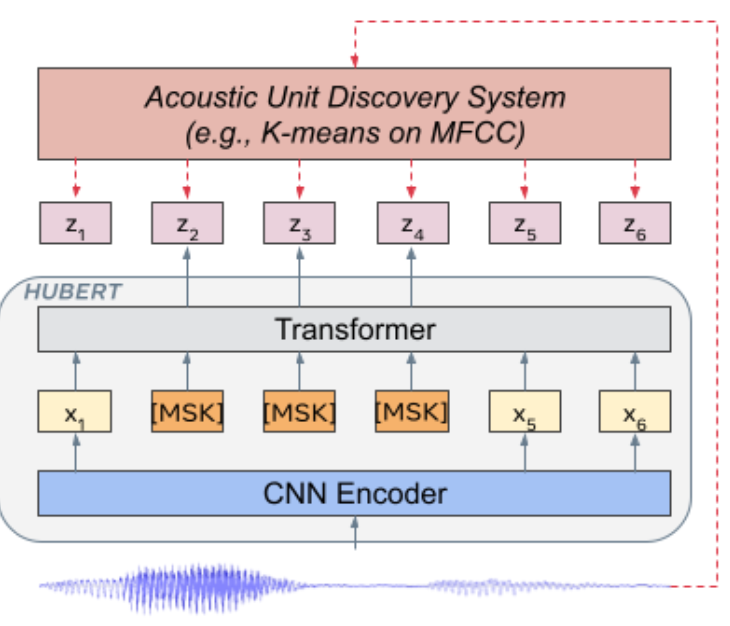
주어진 음성 표현 특징 시퀀스 X = [x1, x2, ..., xT]의 길이 T, M ⊂ [T], 시간 t에서 입력 표현을 xt로 대체하여 손상된 시퀀스 X˜을 얻습니다. HuBERT 인코더 e는 X˜을 입력으로 받아 각 시간 단계에서 타겟 어휘에 대한 출력 분포 p(zt|X, t˜)를 예측하며, 여기서 zt는 음향 단위 발견을 통해 얻은 프레임 수준 타겟입니다.
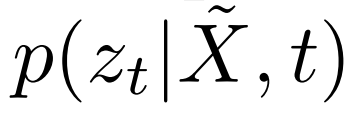
프레임 수준 타겟을 얻기 위해, 음향 단위 발견 모델이 사용됩니다. 주어진 X, 음향 단위 발견 모델 h는 X를 입력으로 받아 h(X) = Z = [z1, z2, ..., zT]를 생성하며, 각 zt는 C-클래스 범주형 분포에 속하고 h는 클러스터링 모델입니다. 우리는 [15]와 동일한 클러스터링 모델, 즉 k-means를 사용합니다.
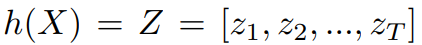
모델을 훈련하는 동안, M은 시작 인덱스로서 p%의 시간 단계를 무작위로 선택하고 그 시작 지점에서 l 단계를 마스킹하여 계산됩니다. 마스킹된 시간 단계에서 교차 엔트로피 손실이 계산됩니다.

인코더 e는 사전 훈련 단계에서 Lm을 최소화하도록 훈련됩니다. 사전 훈련은 여러 반복에 걸쳐 이루어집니다.
초기 반복에서는 클러스터링 모델 h가 MFCC 생성 특징을 사용하여 Z를 생성합니다. 그러나 훈련이 진행됨에 따라, 이전 반복의 HuBERT 모델에서 추출한 잠재 특징을 사용하여 h가 더 나은 타겟 Z를 얻습니다.

4. 텍스트-투-스피치를 위한 데이터 기반 Grapheme-to-Phoneme
최근의 TTS 시스템 [1, 21]은 거의 자연스러운 소리를 생성하는 놀라운 결과를 보여주었습니다. 그러나 이러한 TTS 시스템은 고품질의 음성을 생성하기 위해 동등하게 성능이 높은 G2P 시스템을 필요로 합니다. 잘 수행되는 G2P를 구축하는 것은 전통적인 사전 기반 G2P와 신경망 G2P 모두에게 몇 가지 도전 과제를 제시합니다. 전통적인 G2P 시스템의 경우, 사전을 얻는 것은 번거로운 작업이며 전문가가 필요합니다. 또한, 사전을 얻는다 하더라도, 사전에 없는 단어들에 대한 규칙을 만드는 것은 또 다른 문제를 제기합니다. 신경망 G2P는 추론을 위해 사전을 사용하지 않지만, 훈련 데이터로 사전을 사용합니다.
한편, 언어에 대한 사전을 얻는 것이 번거롭지만, 음성 데이터는 일반적으로 풍부하게 사용 가능합니다. 몇 시간의 음성 데이터에 해당하는 텍스트 전사를 얻는 것은 훨씬 더 현실적입니다. 우리는 레이블이 없는 음성 데이터와 소량의 레이블이 있는 데이터를 시작으로 다음과 같은 새로운 훈련 전략을 제안합니다:
(1) CMU(ARPABET) 또는 IPA와 같은 전통적인 세트와 대조되는 데이터 기반 음소 세트 얻기,
(2) 이 새로운 음소 세트로 신경망 G2P 훈련,
(3) 훈련된 G2P를 사용하여 TTS 시스템 훈련.
이를 달성하기 위해, 우리는 HuBERT 모델의 발견 단계에서 생성된 음향 단위를 음소 표현으로 사용합니다.
클러스터 수(k 값)를 사용하여 음소 세트의 크기를 제어할 수 있습니다. 알고리즘의 흐름도는 그림 1에 나와 있으며 아래에 설명되어 있습니다.
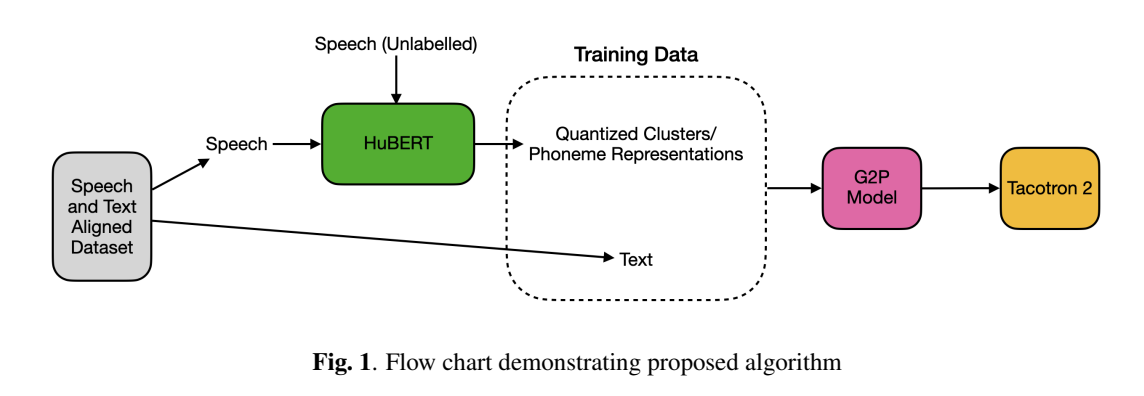
- 레이블이 없는 음성 데이터 Su를 사용하여 HuBERT를 세 번 반복하여 사전 훈련합니다. 처음 반복에서는 MFCC를 사용하고, 이후 중간 트랜스포머 레이어를 사용합니다. 섹션 5를 참조하세요.
- 사전 훈련된 HuBERT 모델이 준비되면, 레이블이 있는 음성 데이터(s1, ..., sn)를 입력하고 9번째 트랜스포머 레이어를 사용하여 음성 특징을 추출하고 k-means 클러스터링을 적용하여 프레임 수준의 음소 타겟(P1, ..., Pn)을 얻습니다. 여기서 각 Pi = h(qi) = [zi1, ...ziT]이고 qi는 e(si)의 9번째 레이어 출력입니다.
- 모든 si에 대해 Pi를 얻은 후, 쌍(Pi, ti)를 사용하여 섹션 2에서 설명한 대로 G2P 트랜스포머 모델을 훈련합니다.
- 훈련된 G2P 모델을 사용하여 섹션 2에서 설명한 Tacotron2 모델을 훈련합니다.
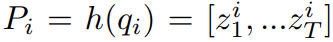

위의 훈련 알고리즘을 사용하여, 우리는 사용할 수 있는 대량의 레이블이 없는 음성 데이터를 활용하고 최소한의 레이블이 있는 훈련 데이터로 고품질의 TTS 모델을 훈련할 수 있습니다.
5. 실험
5.1. HuBERT 모델
첫 단계로, 우리는 95M 파라미터를 가진 HuBERT Base 모델 [15]을 훈련했습니다. 초기 반복에서는 클러스터 타겟을 얻기 위해 39차원의 MFCC 특징을 사용했으며, 이후에는 9번째 트랜스포머 레이어 출력을 사용했습니다.
39차원의 MFCC 특징?
- 기본 MFCC 계수 (13개): 음성 신호의 주파수 성분을 나타냄.
- 델타 계수 (13개): 기본 MFCC 계수의 시간적 변화를 나타냄.
- 델타-델타 계수 (13개): 델타 계수의 시간적 변화를 나타냄.
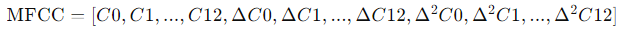
[ 흔한 MFCC 추출 과정 ]
- 프레임 분할: 음성 신호를 짧은 프레임으로 분할. 일반적으로 20-40밀리초(ms) 길이의 프레임을 사용
- 프레임 윈도잉: 각 프레임에 창 함수를 적용하여 신호의 가장자리를 매끄럽게 만든다. 주로 해밍 윈도우(Hamming Window)를 사용.
- FFT (Fast Fourier Transform) 적용: 각 프레임에 대해 FFT를 수행하여 주파수 도메인으로 변환.
- 멜-필터뱅크 적용: FFT 결과에 멜 스케일 필터뱅크를 적용하여 멜 주파수 스펙트럼을 계산. 멜 스케일은 인간의 청각 특성을 반영하여 주파수를 비선형적으로 변환.
- 로그 압축: 멜 스케일 스펙트럼의 각 값을 로그 압축하여 인간의 청각 특성에 맞게 조정.
- DCT (Discrete Cosine Transform) 적용: 로그 멜 스펙트럼에 DCT를 적용하여 멜-주파수 켑스트럼 계수를 얻는다. DCT는 시간 도메인에서의 주파수 성분을 켑스트럼 도메인으로 변환.
총 3번의 반복을 수행했고, 마지막 반복의 9번째 트랜스포머 레이어 출력도 G2P 모델을 훈련하기 위한 최종 음소 타겟을 얻는 데 사용되었습니다.
우리는 LibriSpeech 데이터셋을 사용하여 모델을 사전 훈련했습니다. HuBERT 모델을 사전 훈련하는 데는 960시간의 훈련 세트만 사용했으며, 미세 조정 단계는 수행하지 않았습니다. 마스킹을 위해 무작위로 시간 단계의 8%를 마스크했으며, 마스크 길이는 10-frame으로 설정했습니다. 초기 반복에서는 k-평균 클러스터링에 대해 k=100을 사용했으며, 이후 k=500을 사용했습니다. 그러나 음소 타겟을 얻을 때는 k=100을 사용했습니다. Adam 옵티마이저를 사용하였고, 선형 감쇠 및 최고 학습률 5e-4를 적용했습니다. 학습률은 훈련 단계의 첫 8% 동안 워밍업되었습니다.
[ k 값 설정에 대한 근거 추론 ]
초기에 k=100을 사용한 이유는, 모델이 과도하게 세밀한 특징을 학습하지 않도록 하기 위함이다. 이후 군집이 어느정도 형성되고 나면 점진적으로 세밀한 특징을 학습할 수 있도록 k=500으로 설정.
5.2. G2P 데이터
G2P 모델의 훈련 데이터를 얻기 위해, 약 24시간 분량의 단일 화자 데이터를 포함한 공개된 LJSpeech 데이터셋 [22]을 사용했습니다. 이 데이터셋은 표준 훈련, 검증, 테스트 세트로 각각 8:1:1로 분할했습니다. LJSpeech의 오디오 데이터는 16000으로 다운샘플링한 후 HuBERT에 전달되었습니다. 섹션 5.1에서 언급했듯이, 음소 타겟을 얻기 위해 k-평균 클러스터링에 k=100을 사용했습니다.
섹션 2에서 언급된 규칙 기반 및 신경망 기반의 베이스라인을 훈련하기 위해, 우리는 CMU dict 데이터셋을 사용했습니다. 훈련, 검증, 테스트 세트 분할은 [3]과 동일하게 하여 결과를 직접 비교할 수 있도록 했습니다.
5.3. G2P 모델
G2P 트랜스포머 모델의 경우, 우리는 오픈 소스 툴킷 Deep Phonemizer [23]의 수정된 버전을 사용했습니다. 트랜스포머 입력 특징 크기는 512로 설정했습니다. 인코더와 디코더 모두 트랜스포머 레이어를 4개씩 사용했습니다. 피드포워드 네트워크 크기는 1024로 설정했습니다. 드롭아웃 비율은 0.1을 사용했으며, 4개의 헤드로 구성된 멀티헤드 어텐션을 적용했습니다. Adam 옵티마이저를 사용하여 학습률은 0.0001로 설정했습니다. 입력 텍스트는 네트워크에 전달되기 전에 단어 단위로 분할되었습니다.
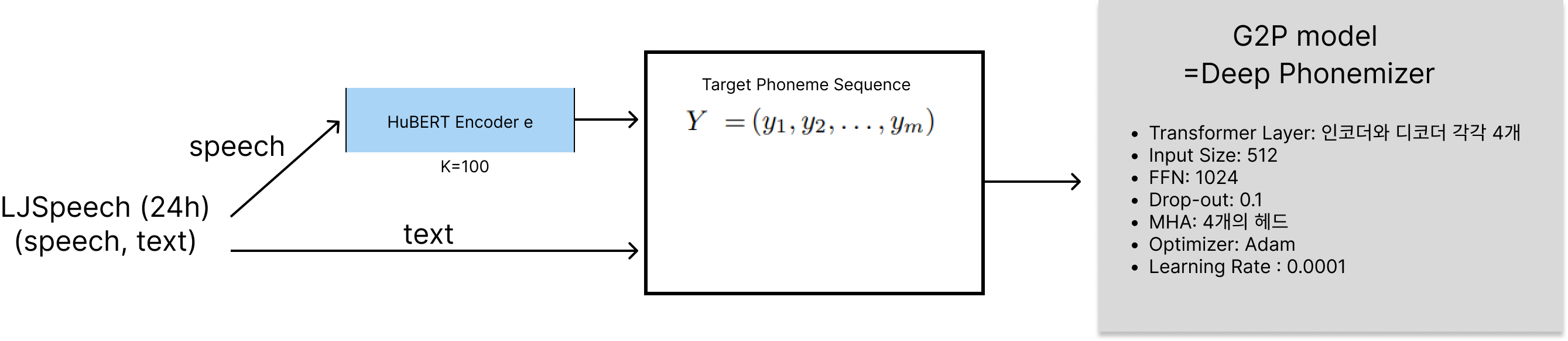
5.4. Tacotron 2
TTS 모델을 구축하고 훈련하기 위해 오픈 소스 TTS 라이브러리 CoquiTTS를 사용했습니다. 원래 샘플링 속도인 22050 Hz 데이터를 다운샘플링 없이 사용했습니다. Adam 옵티마이저를 사용했으며, β1 = 0.9, β2 = 0.998, ϵ = 10-6, 학습률은 1e-4로 설정했습니다. 40dB 미만의 음성 구간은 무음으로 간주하고 데이터셋에서 제거했습니다.
5.5. 평가
모델의 유용성을 평가하고, 우리의 모델을 베이스라인과 비교하기 위해, 골든 평균 의견 점수(GMOS)와 평균 의견 점수(MOS)를 계산했습니다. GMOS와 MOS를 계산하기 위해, 테스트 세트에서 40개의 문장을 합성했습니다. 각 문장은 10명의 평가자가 0.5(“Bad”)에서 5(“Excellent”)까지 0.5 단위로 평가한 10점 리커트 척도로 점수를 매겼습니다. 결과는 95% 신뢰 구간으로 보고합니다.
6. 결과
우리의 G2P 트랜스포머 모델의 품질을 확인하기 위해, 먼저 모델을 훈련하고 표준 CMU dict 데이터셋에서 결과를 얻었습니다.

표 1에서 볼 수 있듯이, 우리 모델은 기존의 최첨단 모델과 비교할 만한 성능을 보였습니다. 훈련을 위해 출력 음소 집합으로 ARPABET 음소 집합을 사용했습니다. 음소 오류율(PER)은 예측된 음소 시퀀스와 CMU dict의 참조 음소 시퀀스 간의 Levenshtein 거리를 계산하여 얻습니다. 여러 발음이 존재하는 경우, 최소 거리를 가진 발음을 사용합니다. 단어 오류율(WER)은 트랜스포머 모델이 예측한 단어 음소 시퀀스 중 정확한 시퀀스의 비율을 측정합니다.
우리 접근법의 유용성을 평가하기 위해, HuBERT 모델을 사용하여 GMOS를 계산했습니다. 이 설정에서는 G2P 모델을 사용하지 않고, 테스트 오디오를 사용하여 HuBERT 모델이 직접 음소 시퀀스를 생성합니다. 모든 HuBERT 구성은 앞서 언급한 것과 동일했습니다. HuBERT 모델에서 얻은 음소를 사용하여 G2P 모델을 훈련하기 때문에, 이러한 음소 시퀀스는 우리에게 golden target과 같으며, 그 품질이 좋다면 HuBERT 출력물을 사용하여 G2P 시스템을 훈련하는 것이 유용하다는 것을 나타냅니다. 테스트 오디오를 사용하여 음소를 생성한 결과, MOS는 4.2±0.06으로, 이는 베이스라인보다 상당히 우수하여 HuBERT 출력을 TTS 시스템의 음소로 사용하는 것의 유용성을 입증합니다.
또한, 섹션 4에 설명된 알고리즘을 사용하여 생성된 사용자 정의 음소 집합을 사용하여, 훈련된 G2P 모델을 전통적인 규칙 기반 G2P [25] 및 사전 훈련된 신경망 G2P와 비교했습니다.

표 2에 나와 있는 결과는 우리의 알고리즘이 전통적인 접근 방식이나 신경망 접근 방식보다 우수한 결과를 생성함을 명확히 보여줍니다. 더 나아가, 우리 접근 방식은 어휘집을 필요로 하지 않으므로 더 널리 사용될 수 있습니다.
6.1. 소거 연구
마지막으로, G2P 모델을 위한 음소 타겟을 생성할 때 클러스터 수(k) 값을 변화시키며 몇 가지 소거 연구를 수행했습니다. 직관적으로, k 값이 크면 더 넓은 범위의 음소를 생성할 수 있으며, 이는 TTS에서 더 나은 오디오 생산을 가능하게 할 것입니다. 그러나 k 값이 너무 크면 다양성에 기여하는 바가 적어지고 모델이 더 무거워질 수 있습니다.
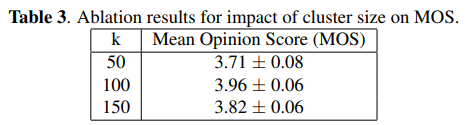
표 3에서 우리는 100 값이 영어의 경우 가장 잘 작동함을 관찰했습니다. 50 값은 존재하는 소리의 다양성을 표현하기에는 너무 작고, 150 값은 너무 높아 성능이 저하되었습니다.
7. 결론
본 연구에서는 데이터를 기반으로 언어의 음소 표현을 얻는 방법을 탐구하였습니다. 우리는 이러한 음소 표현을 사용하여 신경망 그래페임-투-포네임(Grapheme-to-Phoneme, G2P) 모델을 훈련하고, 이를 통해 고품질의 텍스트-투-스피치(Text-to-Speech, TTS) 시스템을 구축하였습니다. 기존의 G2P 모델과 비교해 유사한 성능을 보이면서도, 우리 G2P 모델은 어휘집을 구축하기 위해 도메인 전문가를 필요로 하지 않습니다. 우리의 실험은 영어를 대상으로 수행되었으며, 이전 연구와 결과를 비교했습니다. 마지막으로, 영어에 최적화된 음소 집합의 크기에 대한 소거 연구를 제시했습니다. 우리의 방법은 언어학적 전문 지식을 필요로 하지 않기 때문에, 향후 연구에서는 저자원 언어로 쉽게 확장할 수 있을 것입니다.



