위 논문을 선택한 이유
G2P 관련 연구를 진행하는 도중 찾게 되었다.
G2P에 대한 논문이 최근 논문은 많지 않아서 예전 논문들 부터 쭉 읽어오던 참이다.
처음 읽을 땐 Non-data-driven 방식인건가? 싶었는데, 결국은 Data-driven 방식이었다는 사실... 하하;; (그치만 오히려 좋아)
이 논문을 읽을 때 같이 읽으면 좋을만한 논문들 : T5, ByT5
해당 논문의 기반이 되는 논문이라고 할 수 있겠다!
이 논문 리뷰는 거의 번역본이라고 할 수 있지만, 약간의 개인적인 의견도 첨가되어있음을 밝힌다.
G2P란?
Graphe to Phoneme 의 약자로, 발음에 해당하는 소리를 예측하는 것을 의미한다.
따라서 TTS에서 중요시 되는 과정 중 하나이다.
Abstract
Text-to-Text Transfer Transformer (T5)는 G2P 변환에 사용됨.
(T5가 무엇인지에 대한 설명은 다른 포스팅에서 할 예정. )
T5에 기반한 토크나이저가 관계없는 ByT5는 단어 수준 G2P에 유망한 결과를 보인다. (인풋에 해당하는 UTF-8로 표현)
문장단위, 문단 단위 (=단어보다 더 긴 시퀀스) G2P가 실제 적용과 동철이음어에서 소리와 단어간의 연결 용이하다는 것을 알지만, ByT5는 이 문제에 적합하지 않다.
- 동철이음어
철자가 같지만, 발음이 다른 단어 (영어에서 주로 사용됨 / 한국어는 해당사항 없음)
ex) tear : 1) 찢다[테어] , 2) 눈물[티어]
ByT5는 charater 단위로 진행되기 때문에, decoding 과정이 더 길다.
이는 auto-regressive generation 모델에서 흔히 관찰되는 exposure bias 때문에 성능을 저하시킨다.
따라서, 이를 개선하기 위한 method를 제안한다.
Introduction
G2P 변환은 음성 어휘집을 필요로 하는 모든 작업(STT, ASR)에 필수적이다.
G2P는 크게 2가지로 나뉘는데, 단어수준의 변환과 문장 수준의 변환이 있다.
1) Word-level G2P
한 단어의 발음을 예측하는 TASK
2) Sentence-level G2P
문장 안의 모든 단어들의 발음을 예측하는 TASK
후자가 Context-dependent한 발음을 예측해야 하므로 더 까다로움. (단어들간의 발음 연결성도 고려 필요) 하지만 더 실용적임.
최근 딥러닝에서 Transformer기반 인코더-디코더 모델이 발전해왔다. (ex. T5(Test-To-Text Transfer Transformer)) 특히, T5의 byte 수준의 모델인 ByT5는 token-free 언어모델로 소개 되었는데, 이는 sequence의 각 문자들을 대응하는 UTF-8 인코딩으로 표현한다. ByT5가 단어 수준의 G2P변환에 적절하고 Token-based 모델을 능가함을 보였다.
이 논문에서는 ByT5를 문장 수준으로 확장하였다.
하지만, 이러한 성능에도 불구하고 Transformer기반의 모델들은 exposure bias의 영향을 받는다. Exposure bias는 auto-regressive한 generation모델의 근본적인 문제이다.
Exposure bias는 Maximum likelihood training (teacher forcing) 과 inference과정의 generation porcedure의 차이에서 발생한다. 그 결과, error는 generation 동안에 쌓이고, 디코딩하는 sequence의 길이가 길어질수록 심각한 성능 저하를 일으킨다.
What's Teacher forcnig & Exposure Bias?
Teacher forcing은 sequence 생성 과정에서 바로 앞까지의 sequence 정보를 계속해서 input으로 넣어주는 것
Ex) "I am a student" 라는 문장을 생성하도록 모델을 학습시킨다고 가정하자. (총 4개 sequence로 구성된 문장)
이때, I am 다음에 a라고 맞힐 수도 있지만, not 이라는 엉뚱한 단어를 생성할 가능성도 충분히 있다.
그런데 만약,not을 a로 수정하지 않고, 다음 단계에서 "I am not"이 다음 시퀀스를 예측하도록 하는 input으로 들어가게 되면, 다음 단어 student를 맞히게 될 확률은 더 적어진다.
따라서, 3번째 토큰을 a라고 맞히지 못하였더라도, 강제로 a 로 수정해줌으로써 student를 잘 학습할 수 있도록 하는 것이 Teacher forcing 방법의 예라고 할 수 있다.
이렇게 teacher forcing 방법으로 학습이 완료된 후에, 새로운 문장으로 test 혹은 inference를 한다고 가정해보자!
학습 단계에서는 not이 나와도 a 로 수정해서 student를 출력하도록 teacher-forcning 방법을 사용했지만, test나 inference 단계에서는 teacher-forcing 방법을 사용할 수 없다.
따라서, "I am not a student"라는 전혀 다른 문장이 생성될 수도 있다는 의미다.
이렇게, 추론 단계에서 중간 sequence의 정보를 잘못 예측했을 때, 뒤 sequence까지 영향을 받을 수 있는 문제를 Exposure bias라고 부른다.
(https://jimmy-ai.tistory.com/262 참고)

앞서 말한 exposure bias 때문에,ByT5의 성능은 character수준에 적용하였을 때 decode되는 sequence의 길이가 길어지면서 악화된다. 이 논문에서는 loss-dependent한 sampling 방법을 제안한다. (Two-pass decoding strategy)
이 방법은 sequence안에서 position을 알아차리는 것을 포함하는데, 이는 cross-entropy loss를 모든 위치에서 구함으로서 '잘못된 예측을 했을 확률'을 구한다. 이때 높은 loss값을 갖는 위치들을 학습동안 더 자주 sampling해서, 예측값이 decoder의 input으로 들어가기 전에 ground-truth로 대체되도록 한다.
이로써 모델이 이러한 error들로부터 학습하고 correct하는 능력을 향상시킨다. 이 과정속에서 adaptive-sampling ratio를 사용하는데, 이는 이전 epoch에서의 PER(Phoneme Error Rate)에 의해 결정된다.
연구 결과, 이러한 loss-dependent sampling 방법이 전반적인 English G2P 벤치마크에서 성능 향상을 보였고, exposure bias의 감소를 보임을 확인하였다. 게다가 향상된 phoneme prediction 을 보이는 예시들을 나타내었다.
Related Work
Grapheme-to-Phoneme (G2P) Conversion
- Non-Data-drive 방식 2가지
1) 기존의 G2P는 발음사전에 기반하였다. 발음사전은 letter sequence에 해당하는 발음을 찾아볼 수 있었다.
그러나, 사전의 크기가 매우 커서 비용적 측면에서 좋지 않고, 유한한 사전의 크기 때문에 한계가 있었다.
2) 또다른 기존의 방법으로는 rule-based 모델이 있는데, 이는 pre-defined phonetic 규칙에 의해 모든 letter (dubsequence)의 발음이 규정되었다.
하지만 이는 매우 어렵고 불규칙적이거나 복합한 규칙 (그러나 일상에서 흔히 사용되는) 을 잡아내기 어려웠다.
- Data-driven 방식
이러한 한계점들을 극복하기 위해 대규모 data-set에서 복잡한 음성 규칙을 완화할 수 있는 data-driven stochastic approach를 사용했다. 이 approach는 weighted finite state transducer를 포함한다.
시간이 흐름에 따라, G2P변환 연구는 딥러닝 기반 방법론으로 방향을 틀었다. 최근 transformer 기반 모델들이 (sequencial datd의 long-term dependency에 효율적이므로) G2P 변환에 강력한 성능을 보였다. 특히 T5가 다양한 NLP task에 쓰이는 만큼 G2P에서도 널리 사용되었다.
Token-free Language Model (ByT5)
최근 단어 token을 사용하지 않는 token-free 모델이 NLP에 등장했다. 이는 UTF-8 인코딩을 인풋으로 사용하였는데, 전통적인 T5 모델보다 더 나은 성능을 보였다.
Word, subword에 대응하는 token을 사용하지 않기 때문에, 모르는 단어(unknown vocabulary)에 대해서도 처리가 가능하다. 이는mT5(multilingual T5) 에 비해 언어의 넓은 변동성을 높은 성능으로 처리할 수 있다.
Exposure Bias
Transformer 기반 모델은 exposure bias 문제를 겪는다. Exposure bias는 training과 test-time generation에서의 차이로 인해 생긴다. 모델은 ground-truth data의 분포로 학습이 되는 반면 test 할때는 모델이 sampling한 prefix sequence에 기반하여 next token을 예측한다. 그 결과, error가 generation하는 동안 계속 쌓이고 축적되어 문장의 길이가 길어질수록 성능 저하를 야기한다.
이러한 문제를 완화시키기 위한 몇몇 시도들이 있었다.
- ground-truth sequence를 대체하거나 교란하는 방법이다. 어떤 저자들은 error의 축적문제는 더 나은 decoding method로 해결할 수 있다고 말한다.
- MLE에서 문제를 찾아서, (강화학습 또는 generative adversarial network를 포함한) non-MLE 방식을 도입한 반면, He 저자는 MLE 훈련에서 Exposure bias 의 영향에 대한 의문을 제기했다.
Exposure bias가 정말 문제인지 아닌지에 대한 뜨거운 논쟁이 지속되는 동안, Arora 저자는 exposure bias에 대해 정량화 가능한 정의를 내렸고, exposure bias로 인한 error의 축적이 generation동안 실제로 발생한다는 것을 보였다.
Loss-based Sampling
input sequence X = [x_0,x_1, ..., x_n]
output phoneme sequence Y = [y_0, y_1, ..., y_t]
mapping model p_seta
- p_seta를 학습시키는 것은 주로 teacher forcing 사용.
- 디코더가 이전 시퀀스 발음 정보를 기반으로 다음 발음을 예측하도록 학습시키는 것.
- 다음 B라는 배치 안에서 negative log-likelihood 를 최소화 시키는 방향으로 학습.

y_i 는 i번째 step에서 생성된 phoneme. y^(i-1)_0는 i번째 step에서의 context.
그러나, inference 도중, target sequence를 만들어내는 가장 심플한 방법은 auto-regressive하게 sequence를 sampling 하는 것이다. 즉, 각 i번째 step에서 가장 가능성 있는 걸 선택.

이 과정은 시퀀스 길이 제한이 걸릴때까지 진행되거나, <EOS>와 같은 unique token이 만들어질때까지 진행.
학습과 추론과정의 목표가 다르기 때문에(=exposure bias), auto-regressive 생성 모델은 decoding해야하는 시퀀스의 길이가 길어질수록 성능이 저하된다.
Loss-Based Sampling for Exposure Bias Mitigation
- 기존) Smapling-based training
exposure bias를 완화하기 위해 gold-target sequence를 poredicted sequence와 랜덤하게 섞는다.
- 제안) Loss-based training
잘못 예측한 확률의 위치를 파악하기 위해 제안한 방법.
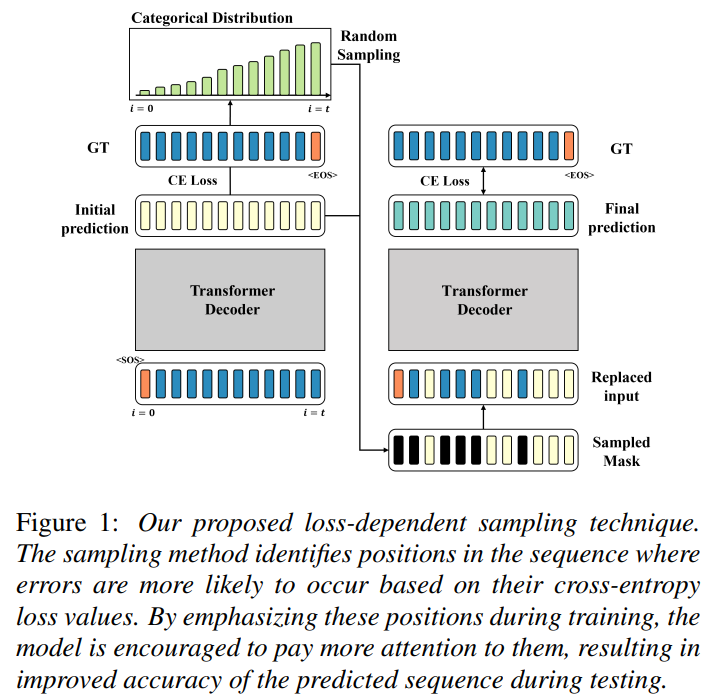
- input으로 ground-truth phoneme sequence를 넣고, 각 i번째 step에서의 예측 확률을 얻는다.
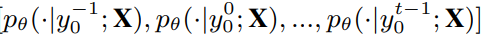
- ground-truth phoneme 의 one-hot encoding 과 확률분포의 cross-entropy loss 를 얻는다.
* 이 과정에서는 gradient를 구하지 않는다.
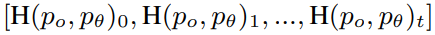
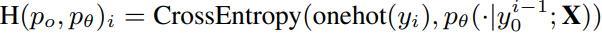
- 범주형분포를 얻기 위해 cross-entropy loss를 normalize 함.
- 분포에서 교체 없이 특정 시간 단계 수를 무작위로 샘플링 하여 각 실제 입력을 해당 예측으로 바꿀 것인지 여부를 결정하는 mask를 만든다.
- 이 샘플링 과정 동안 우리는 이전 에폭의 PER(Phoneme Error Rate)로 Adaptive하게 샘플링 비율을 사용하여, 원하는 대테 횟수를 결정한다. loss-based sampling에서 얻은 대체 시퀀스는 다시 한 번 decoder의 입력으로 사용된다.
- 두 번째 예측은, 무작위로 샘플링된 예측을 기반으로 생성되므로, 결과 출력이 auto-regressive behavior을 반영할 수 있다.
- 두 번째 예측에서 계산된 Cross-entropy loss는 최종 loss이며 역전파에 사용된다.
우리가 제안한 손실 기반 샘플링 기술을 사용하면 모델이 훈련 중에 오류가 발생할 가능성이 더 높은 시퀀스 위치에 집중할 수 있다. 고로 이러한 오류로부터 학습하고 수정하는 능력을 향상시킬 수 있다.
테스트 중 longer sequence에 대한 성능이 향상되어, 우리가 제안한 방식의 효율성을 입증하였다.
부가설명
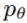
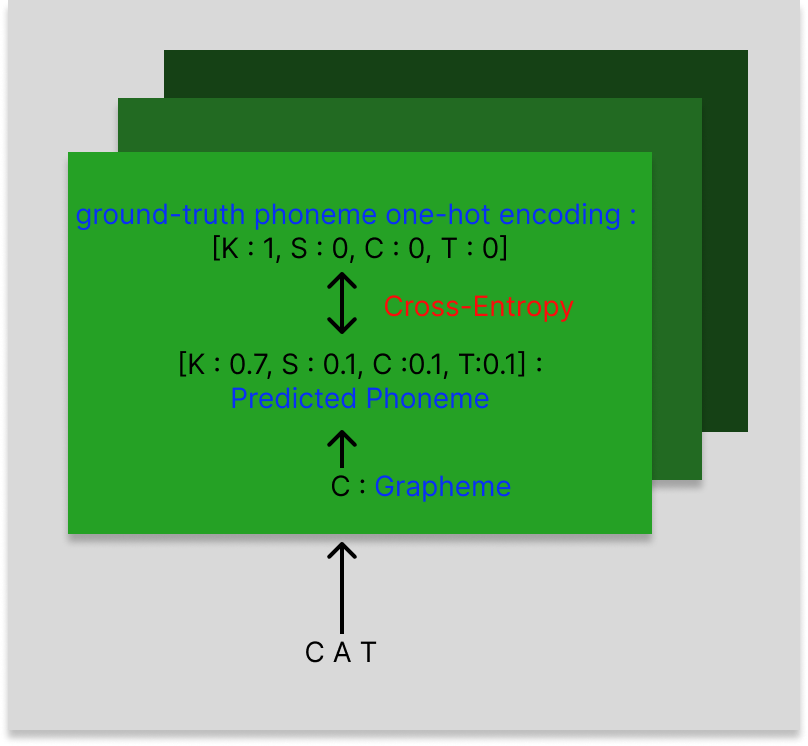
Input과 Output을 mapping 해주는 함수.
ex) Input Grapheme : [ h e l l o ]
Output Phoneme : [h əˈ l o ʊ] 각 글자가 실제로 발음되는 소리
많은 양의 그래페임-폰임 데이터 쌍을 사용하여 학습! (Data-driven : 올바르게 변환하는 규칙과 패턴 학습)
Cross Entropy Loss
그래프에서 모델의 예측 확률 분포와 실제 레이블의 분포를 비교하여 손실을 계산
- 실제 레이블 분포 (True Label Distribution):
- 실제 레이블 분포는 주어진 입력 데이터에 대한 실제 클래스 레이블을 나타내는 확률 분포입니다. 이 분포는 보통 원-핫 인코딩(one-hot encoding) 방식으로 표현됩니다.
- 예를 들어, 3개의 클래스(A, B, C)가 있는 문제에서 실제 클래스가 B라면, 실제 레이블 분포는 [0, 1, 0]이 됩니다. 즉, 실제 레이블 분포는 해당 클래스에 1의 확률을 부여하고 나머지 클래스에 0의 확률을 부여합니다.
- 모델의 예측 분포 (Predicted Probability Distribution):
- 모델의 예측 분포는 주어진 입력 데이터에 대해 모델이 출력한 클래스별 예측 확률을 나타냅니다.
- 예를 들어, 모델이 입력 데이터에 대해 [0.2, 0.7, 0.1]의 확률을 출력했다면, 이는 모델이 클래스 A, B, C에 대해 각각 20%, 70%, 10%의 확률을 부여한 것입니다.
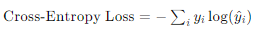
- 는 실제 레이블의 i번째 클래스 확률 (원-핫 인코딩된 값).
- y^i\hat는 모델이 예측한 i번째 클래스 확률.
변경된 식 :
Evaluation of Exposure Bias
Arora 저자가 제안한 방법)
- 예상되는 단계별 예측 손실의 시간 누적 사용.
- 디코더는 매 i번째 time step마다 예측된 발음의 확률분포를 만드는데, 이는 이전 발음 시퀀스

에 기반하여 계산된다.
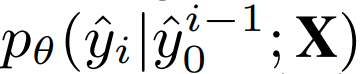
이렇게 예측된 분포는 ,
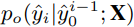
와 견주어, 단계별 auto-regressive prediction loss를 계산한다.
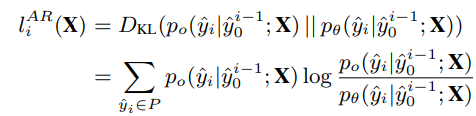
- Loss는 evaluation set D_e에 대해 평균값을 취한다. (예상되는 단계별 auto-regressive loss를 근사화하기 위함)

- 비슷하게, 예측값을 groud-truth로 바꾸면서, 단계별 teacher forcing losses를 얻는다.
따라서, exposure bias이 없다고 가정한다.
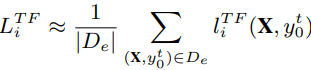
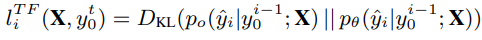
- 그런 다음, l단계까지 예상되는 Teacher forcing losses에 대해 예상되는 auto-regressive prediction loss의 누적으로 정의되는 AccErr 을 제안함.
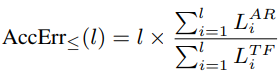
- 이 metric은 적절한 가정 하에 l과 l^2 간의 값을 갖는다.
- l 값은 최대 l 길이의 sequence에 대한 exposure bias가 없음을 의미한다.
- 반면에, l 에서 AccErr의 높은 편차는 l 길이의 sequence에 대한 높은 exposure bias를 의미한다.
- 최악의 상황으로는, metric이 phoneme sequence length와 함께 quadratic하게 증가하는 것이다.

Experimental Settings
Dataset and Model
| TIMIT | - Corpus which contains 6300 spoken sentences. - 미국 영어의 8개 주요 방언 지역에서 온 630명의 화자가 각 10개 문장씩 말함. - Time-aligned orthographic and phonetic transcription을 제공. -> G2P 변환 task에 사용 가능. |
- Training :
sentence-level에서의 G2P를 수행하기 위해, 3개 문장씩 concat 하여 사용. (random하게 select) - Test :
2개의 subset 생성. (short-3문장 / long- 최대 5문장) - Model :
ByT5 이용 - token-free model - ByT5-small (300M parameters, 단어 수준 G2P pre-trained 모델)를 finetuning 하는 방식으로 진행.
Training Details
- Optimizer : Adam
- Weight decay : 5 x 10^(-3)
- Learning rate : 10^(-5)
- Batch size : 32
- Gradient clipping : 5.0 Maximum gradient.
- Fixed sample ratio : chosen by grid search (0.1, 0.3, 0.6, 0.9} - 각 실험에서 최적을 찾아 사용.
- NVIDIA Quadro RTX 8000
Results
제안된 손실 기반 샘플링 방법은 기존 방법들에 비해 향상된 성능을 보여주었습니다. 모델의 음소 오류율(Phoneme Error Rate, PER)과 단어 오류율(Word Error Rate, WER)이 두 테스트 세트 모두에서 손실 기반 샘플링 기법을 사용했을 때 균일 샘플링 및 전통적인 교사 강요 방법에 비해 감소하였습니다.



