꽤 오랫동안 트랜스포머는 인코더-디코더 기반 모델, 버트는 인코더 기반 pre-trained 된 모델.. 이라고만 알아왔던 나를 반성하면서 이젠 진짜 명확하게 할 필요가 있다.
먼저 Transformer에 대해 알아보자.
Transformer의 가장 큰 아이디어는 self-attention 이다.
이를 이해하기 위해서 먼저 attention이라는 개념에 대해 정확히 알자.

Attention
입력된 모든 정보에 집중하는 것이 아니라, 소수의 정보에만 집중하는 것을 일컫는다. 예를 들어 어떤 남자가 강아지와 산책하는 그림이 있다고 하자. 주변 배경에 집중할 필요 없이 강아지와 남자에 집중하여 중요한 정보를 캐치하는 것이 중요할 것이다.
그럼 Attention이라는 개념이 왜 등장하게 되었을까?
이를 알기 위해서 Seq2Seq 모델에 대한 이해가 필요하다. 이는 다음 포스팅에서 더 자세히 알기로 하고, 여기서는 간략히만 알아보자.
Seq2Seq
Seq2Seq 모델이란 입력을 Sequence로 받고 Sequence를 출력하는 번역, 요약과 같은 작업을 위해 고안된 RNN 기반 모델이다.
예를 들어, "나는 학생입니다" 라는 문장을 Input으로 넣었다고 하자.
Encoder를 거쳐 context vector(문맥정보를 포함하는 벡터)를 생성할 것이다. 그럼 여기에 <sos>라는 문장의 시작을 의미하는 special token을 더하여 Decoder의 입력값으로 넣는다. Decoder의 출력으로 "I am a student"가 나오게 되는 일련의 과정을 거친다.
대표적으로 RNN 구조에 대해 알아보자.
1. Encoder의 Hidden state (은닉상태)를 적절한 값으로 초기화 한다.
2. 매 시점(time step)마다 원문의 단어(token)가 입력되면, Encoder는 이를 이용해 Hidden state를 Update한다.
3. 최종 Hidden state는 입력 sequence의 압축 요약된 정보를 담게 된다. => 이를 Context Vector라고 한다.
4. Context vector를 Decoder에 넘긴다.
5. Decoder는 전달받은 Context Vector로 자신의 Hidden state를 초기화한다.
6. 매 시점(time step) 바로 직전 시점에 출력했던 단어를 입력받아, Hidden state를 update한다.
7. <eos> 토큰이 나올때까지 위 과정(6번과정)을 반복한다.
Seq2Seq 구조의 문제점
자세한 설명은 Seq2Seq 포스팅에서 할 예정. [Code 예시 첨부]
- RNN : (Shorter Reference Window) 짧은 참조 윈도우 크기를 갖는 문제.
: 입력이 길어지면, 주어진 sequence보다 긴 입력을 고려하지 못한다는 문제. - GRU, LSTM : RNN보다는 긴 위도우 크기를 갖지만, 그래도 그 길이가 무한하지 않다는 문제.
- Shared Problem
1. 병렬처리가 되지 않는다.
: 학습속도가 느리다.
2. Long Distance Dependency 문제.
: Gradient Vanishing / Exploding Gradient 문제
위와 같은 문제를 해결하는 방법으로 Attention Mechanism이 등장했다.
Attention이 등장한 배경에는 엄청난 컴퓨팅 리소스가 뒷받침하고 있다는 것을 명심해야 한다.
Attention의 등장이 어떤 영향을 미쳤을까?
- 무한한 크기의 윈도우크기를 갖는다. (*무한한 길이의 입력이라는 말이 아니다! 입력 길이는 제한되어 있지만, 주어진 모든 입력에 대해 위도우크기가 무한하다는 의미임을 명심하자!) 따라서 sequence가 담고 있는 전체적인 문맥을 파악하고 반영할 수 있어졌다.
- Q가 모든 K를 비교하므로, 병렬처리가 가능하다. 이는 학습 속도를 향상시키고, 엄청난 크기의 데이터셋에 대한 학습이 가능하게 한다.
Self-Attention
: attention과 self-attention의 가장 큰 차이는, self가 붙었으니 같은 문장 내에서 문장 내 단어(Token)간의 관계를 파악하는 방법이다.
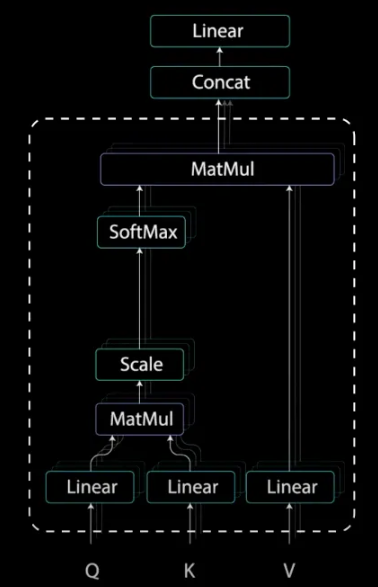
Q,K,V가 필요한 이유가 뭘까?
self-attention은 하나의 문장에 대해서 3가지 방면으로 본다고 생각하자. 아래와 같이 생각하는 것이 편하다.
Q : 내가 인터넷에 검색하는 문장
K : 인터넷에 검색했을 때 보이는 제목들
V : 제목을 클릭해서 들어간 안의 내용
그럼 Q,K,V가 만들어지는 과정에 대해 알아보자.
Input Embedding
임베딩이란, 인간의 언어를 컴퓨터가 이해할 수 있도록 digit으로 바꿔주는 과정을 의미한다.
입력된 문장을 token 단위로 나눈 뒤에, 각 토큰을 숫자로 변환한다. 이때 숫자는 scalar일 필요는 없고 vector로도 표현이 가능하다.
예를 들어, apple = [1,3,5,2,4,14] 라고 표현했다고 해보자. 이때 임베딩 차원 d = 6이라고 한다.
- Word2Vec
약 3-5만개의 Vocab의 정보를 가지고 있는 단어사전에서, 컴퓨터가 이해할 수 있도록 id 값으로 변환해준다.
하지만, 이 방법의 가장 큰 문제점은 단어의 위치를 고려하지 않고, 같은 단어는 무조건 같은 값을 할당한다는 것이다.
예를 들어, "I am a student. I do not drink." 라는 문장과 " I am not a student. I do drink" 라는 문장을 보자.
not 의 위치만 바뀌었을 뿐인데, 문장의 의미가 전혀 달라지는 것을 확인하 수 있다. 이런 경우에도 Word2Vec은 not이 어떤 것을 부정하고 있는지와 관계없이 같은 임베딩값을 부여한다.
이와 같이, 단어의 순서를 고려하는 것은 매우 중요한 문제이다. 그래서 별도로 Positional Encoding을 진행한다.
Positional Encoding
: 입력 임베딩에, 입력 임베딩과 같은 차원의 위치정보를 담고 있는 벡터를 더해주는 과정.
- ex) 입력 임베딩의 차원을 d라고 할 때, p번째 단어(token)의 positional encoding은 다음과 같이 진행한다.
위치정보를 전달하는 방법은 매우 다양한데, 가장 쉽게 생각할 수 있는 방법은 문장의 순서대로 index를 부여하는 방법이다.
예를 들어 "I am a student" 라는 문장을 보자. 그럼 각 token(단어)에 I [0], am [1], a [2], student[3] 라고 0부터 3까지 값을 부여할 수도 있지만, 이렇게 위치정보를 전달하게 되면, 뒤에 있는 단어일수록 큰 값을 부여받아, word embedding 당시에 부여받은 단어의 의미적 정보가 훼손될 수 있다.
마찬가지로 0부터 1사이 값을 소숫점 단위로 나눠 순서대로 부여한다고 해도 의미적 정보가 훼손될 수 있다.
이외에도 Absolute Position Embedding (APE), Relative Position Embedding (RPE) 등 다양한 방법이 있는데, 나머지는 다른 포스팅에서 다루기로 하고, 오늘은 Transformer에서 제안한 positional encoding 방법에 대해서만 설명하겠다.
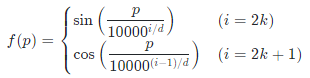

이 수식을 자세히 보면, 짝수번째 토큰에 대해서는 sin 함수를 적용하고, 홀수번째 토큰에 대해서는 cosine 함수를 적용했다. sin함수와 cos함수의 가장 큰 특징은 바로 "주기함수"라는 것이다.
주기함수는 일정한 구간을 기준으로 형태가 반복한다. sin 함수나 cos 함수 중 한가지만 적용했을 경우, 그 주기 안에 입력 sequence를 전부 담지 못할 수도 있기 때문에 2개의 주기함수를 섞어서 사용했다. 이보다 더 긴 주기의 문장/토큰은 서로 의미적인 중요도가 떨어진다고 보는 가정이 내포되어 있기도 하다. 그만큼, 웬만한 시퀀스를 아우를 수 있다는 말이기도 하다.
Q, K, V 생성
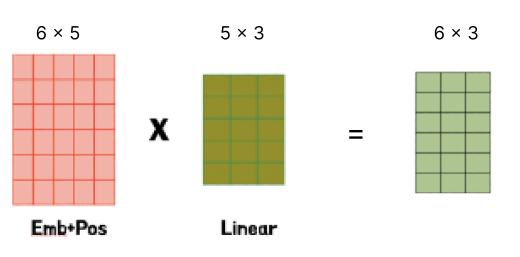
입력 문장에 Word-embedding + Positional Encoding을 마친 Position-aware Embedding(위치 정보를 포함한 임베딩)을 복사하여 Q,K,V를 만든다. 즉, 이 상태에서 Q,K,V는 똑같은 모습(같은 크기, 같은 임베딩)인거다!
지금부터 Input이 들어간 흐름대로 설명하겠다.
1) Linear
앞에서 말했다시피 각 linear는 Q,K,V라고 생각하면 된다. 그 중에서도 Q와 K의 유사도를 계산하는 과정이 먼저 수행된다.
1번부터 4번까지 과정은 모두 Q와 K의 관계를 구하는 과정이라고 봐도 무관하다.
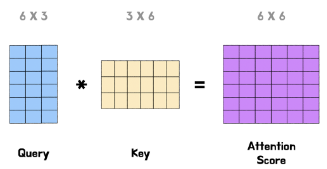
2) Q와 K의 MatMul
Linear 변환을 마친 Q와 Transpose K를 dot-product를 통해 연산한다. 이렇게 계산된 Matrix를 "Attention Filter"라고 부른다.
처음에는 random한 값이겠지만, 한 번의 학습과정을 마치면 모두 유의미한 값으로 채워진다.
3) Scale
위에서 만들어진 Attention Filter안의 값들은 Attention Score라고 부르는데, 이를 K의 차원의 제곱근으로 scaling한다.
여기서는 6이 되겠다. (어차피 Q나 K의 차원이 같지만, 보통 root(d_k) 라고 한다.)
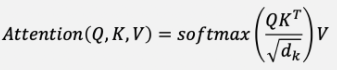
softmax 함수 안에 있는 값을 보자.
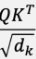
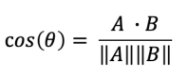
이건 우리가 잘 아는 코사인 유사도 공식이다. -1부터 1 사이의 값을 갖는데, 1에 가까워질수록 유사하고 -1에 가까울수록 유사하지 않다는 의미이다.
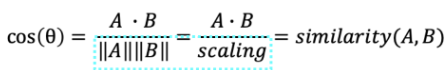
즉, 코사인 유사도는 두 벡터의 곱을, 두 벡터의 L2 norm 값으로 scaling 한 것이다. 즉 두 벡터의 유사도를 구하는 벡터 유사도인 것이다.
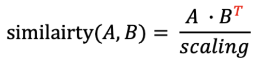
이처럼 행렬 유사도도 구할 수 있다. 행렬 A와 행렬 B의 유사도로 행렬 유사도를 구할 수 있다. 이때, 행렬의 곱을 위해서는 후자를 전치시켜야 한다.
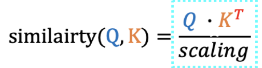
결국, Q와 K의 유사도 형태로 나타낼 수 있다.

이때, Scaling Factor는 Key's dimension 크기에 따라 결정된다.
scaling을 하는 이유는?
softmax를 했을 때 최대한 많은 gradient를 살리기 위함이다.
dot-product의 특성상, 문장의 길이가 길어질수록 큰 값을 갖게 된다.
이후 softmax를 취할 때, 0과 1사이의 값으로 매핑시켜주는데, 이때 score간의 차이가 너무 크면, 특정값들만 과도하게 살아남고 나머지는 죽어버리는 경우가 생긴다.
따라서, softmax를 최대한 비슷한 값들 사이에서 진행시키기 위해 scaling을 진행하는 것이다.
3.5) Mask (Opt.)
이 과정은 필수는 아니고 Optional 한 과정이다.
입력 문장 중 word인지 아닌지를 Masking 여부를 통해 구분하는 기능을 수행한다.
== word 입력이 끝난 후 Padding 처리하는 것과 동일하다는데, 이 부분은 아직 내가 이해가 안 되었다... (아는 분 설명 좀..)
4) Softmax
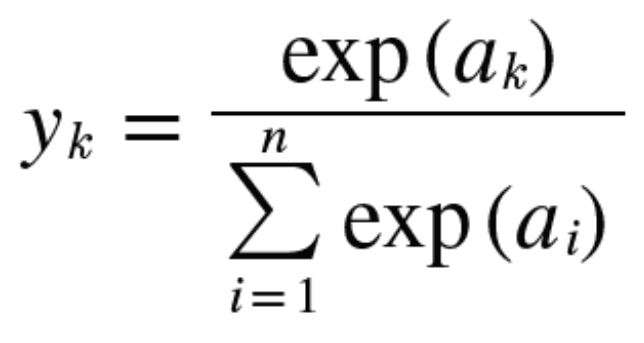
softmax 는 결과값을 0과 1사이의 값으로 변환하는 함수이다.
이렇게 0과 1사이값으로 나타내어진 attention filter가 value와 곱해져(내적), 불필요한 정보들의 비중은 줄이고, 중요한 정보에 집중할 수 있도록 한다.
5) V와 MatMul
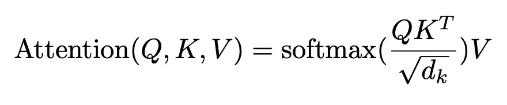
여기까지가 하나의 Head에서 일어나는 일련의 과정들을 정리해 둔 것이다.
5개의 Layer(MatMul, Scale, Mask(Opt.), SoftMax, MatMul) 을 거치는 나름 복잡한 과정을 거친다.
MHA
Transformer에서 가장 크게 기여한 바 중에 하나가 또 Multi Head Attention (MHA) 이다.
즉, 위 과정이 동시에 여러개가 진행된다는 뜻이다.
여러개의 Head -> 여러개의 Attention Filter 생성 -> 여러개의 자체 필터링된 V 행렬 출력
입력된 같은 문장에 대해서 여러 방면으로 학습한다는 말은,
여러개의 self-attention layers이 있어, 각각 Head들이 같은 입력에 대해 다른 언어 현상을 학습하게 된다는 뜻이다.
같은 문장이 입력되더라도, 각각의 Head들이 서로 다른 Filter를 생성해 서로 다른 언어적 특성에 집중하도록 한다.
근데 왜 서로 다른 filter가 생성될까?
같은 임베딩 과정을 거치면 결국 여러개의 filter가 다 똑같아 지는 거 아닌가?
random 초기화를 시키나? 아니면 word embedding 과정이 다른가? 이 부분이 또 이해가 잘 안 간다.,
최종적으로 모델을 정할 때, 원하는 Task에 맞게 Head의 수 (=생성하고자 하는 attention filter의 수) 를 정해주어야 한다.
그 Output을 Concat을 통해 Linear Layer에 통과시켜 원하는 출력크기를 갖추게 된다.
Referece
[1] Attention Is All You Need
: https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
[2]트랜스포머(Transformer)와 어텐션 매커니즘(Attention Mechanism)이란 무엇인가?: https://velog.io/@jhbale11/%EC%96%B4%ED%85%90%EC%85%98-%EB%A7%A4%EC%BB%A4%EB%8B%88%EC%A6%98Attention-Mechanism%EC%9D%B4%EB%9E%80-%EB%AC%B4%EC%97%87%EC%9D%B8%EA%B0%80
[3]Illustrated Guide to Transformers- Step by Step Explanation
: https://towardsdatascience.com/illustrated-guide-to-transformers-step-by-step-explanation-f74876522bc0
[4] MHA 파헤치기
: https://www.blossominkyung.com/deeplearning/transformer-mha
'AI > Language' 카테고리의 다른 글
| [Paper Review] A Survey on Multimodal Large Language Model (MLLM) (2) | 2024.08.22 |
|---|---|
| ROFORMER: ENHANCED TRANSFORMER WITH ROTARYPOSITION EMBEDDING (12) | 2024.07.23 |
| [Paper Translate] A SURVEY ON RECENT ADVANCES IN NAMED ENTITYRECOGNITION (5) | 2024.07.16 |
| MCL-NER short breif (1) | 2024.07.03 |
| Shortened LLaMA (1) | 2024.06.01 |


