[ 사전 개념 ]
* Width Pruning :
어텐션 헤드의 개수를 줄이는 방법들처럼, 레이어의 개수는 유지하되 projection weight matrices size를 줄이는 방법
batch size가 제한된 생황에서 width pruning 방식은 inference speed를 향상시키는 데에 전혀 도움이 되지 않았다.
* Depth Pruning :
weights의 사이즈는 유지하되, layers or blocks의 개수를 줄이는 방법
상대적으로 크고 거칠게 pruning하는 방법이라 width pruning보다 덜 효율적일거라고 생각하지만, simple depth pruning과 LoRA 방식이 혼용된 방법이 zero-shot에서 최근 연구들과 경쟁할만한 결과를 보임.
게다가, depth-pruning 방식이 memeory limit으로 batch size가 제한되어 있는 상황에서 inference speed를 눈에띄게 향상시킴.
LLM의 발전은 다양한 linguistic tasks들을 잘 해결할 수 있는 방향으로 발전해 왔지만, high computational demands가 있다. 이를 실용적이고 접근 가능하게 만들기 위해 다양한 optimization 연구들이 진행되어 왔다. (ex. compression)
[기존의 유명한 방법들 소개]
layers 수는 유지하되 network의 너비를 줄이는 방법들 (coupled structures를 제거)
* LLM-Pruner :
* FLAP :
network의 너비를 줄이면서, 몇몇 레이어들은 통째로 제거하는 방법
*Sheared LLaMA :
[문제 인식]
깊이와 너비 측면에서 모두pruning을 하는 방법이 존재함에도 불구하고, 이 두 측면이 LLM에 어떻게 영향을 미치는가에 대한 연구는 없다.
성능을 향상시키기 위해 배치사이즈를 높이는 것이 GPU 활용 및 처리량 측면에서 기본적인 방법이지만, 이는 제한이 있는 GPU 상황에서는 매우 취약하다. 고로, simple-depth pruning 방식과 LoRA방식을 혼용하여 zero-shot 작업 능력 측면에서 최근 연구들과 심층 비교 진행.

파란선이 본 논문의 방법론.
왼쪽 표) 타 모델들은 파라미터의 수가 작으면 latency가 크고, 늘어날수록 latency가 줄어든다.
오른쪽 표) 타 모델들에 비해 처리량에 따른 latency가 적은 것을 알 수 있다.
간단하지만 효과적인 깊이 가지치기 방식 소개하기 위해 prunable units, 중요도 평가 기준, 재교육 빈도 등 의 선택을 포함한 다양한 design factor들을 설정하여 심층분석 진행.
Method : Block Pruning

기본적으로 LLM은 multiple transformer가 stack되어 있는 구조이다. (MHA 와 FFN이 한 쌍으로 구성되어 있다고 보자)
바로 이 transformer block을 prunable unit으로 설정함.
-> 추론의 지연을 줄이는 효과
결론적으로는, one-shot pruning 진행 후 한 번의 재학습 진행.
Q. 어떻게 block의 중요성을 판단할까?
Talyor+ and PPL metrics 를 사용하자.
1) criteria to evaluate the significance of each block
Linear weighted matrices :
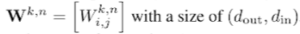
(k 는 type of operation within n-th transformer block -> query projection of MHA / up projection in FFN)
weighted importance score 계산 방법 :출력 뉴론 수준에서 계산된 후, 합산한다.
2) Magnitude (Mag)
더 작은 norms을 갖는 가중치는 덜 유익하다는 가정 하에 진행.
블록 수준에서, 아래 식 계산 : 가중치 절대값 단순 합 개념

3) Taylor :2차 테일러 근사 사용
weight parameters를 제거하여 생긴 에러를 측정하는 것은 그것의 중요도를 판단하는데 도움이 된다.
교정 데이터셋 D가 주어졌을 때, training loss 는 다음과 같이 변경된다. (2차 미분 진행)

따라서, 우리는 block score를 다음과 같이 정의한다.

4) Mag+ and Taylor+
앞선 계산방식에 따르면 중요하지 않은 정도를 측정할 수 있지만, 그들을 제거하면 심각한 성능 하락이 뛰다른다.
Similar to a popular heuristic, 그래서 첫 4개와 마지막 2개 blocks은 보존한다. (pruning candidates에서 제외)
5) Perplexity (PPL)
불필요한 blocks은 모델의 출력에 기여를 덜 하고, 그것들을 제거하면 PPL의 저하가 줄어든다.
-> 이는 language modeling tasks에서 흔히 사용되는 metric.
이런 관점에서, 물리적으로 각 block들을 제거하고, 그것이 PPL에 미치는 영향을 교정 데이터셋 D를 사용하여 모니터링 함.

PPL의 사용은 다음 토큰 예측 손실로부터 파생되어 모델의 동작을 반영한다.
역전파 기울기와 헤시안 역을 계산하거나 마스크 학습 단계를 포함할 필요 없이 forward 전달만 필요.
그림4에서 보다시피, 몇 blocks은 PPL metric에 slight한 영향을 줌을 보여, 제거대상으로 성별됨. 맨 처음과 마지막 블록의 제거는 성능의 급격한 하락을 보임. 고로, 제거 대상에서 제외할 필요 있음.

Perplexity에 대해 알아보자~!
Perplexity는 BLEU, ROUGE와 더불어 언어모델의 Generation 성능을 판단할 수 있는 지표이다.
문장 𝑊의 길이가 𝑁이라고 하였을 때의 PPL은 다음과 같다.

문장의 확률에 체인룰(chain rule)을 적용하면 아래와 같습니다.
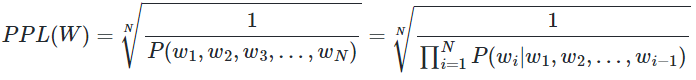
여기에 n-gram을 적용하면 다음과 같습니다.

Perplexity는 테스트 세트 문장의 발생 확률의 역수를 단어 수로 정규화 하여 계산됨.
따라서, Perplexity가 높다는 것은 언어모델이 매 순간 골라야할 가짓수가 많아 혼란스러워 함을 의미함.
참고) https://wikidocs.net/21697
One-shot pruning
block 단위에서 중요성을 기준으로 정렬 후 하나씩 제거해봄.
실험적으로 몇 개의 블록이 제거되어야 원하는 모델의 사이즈를 맞출 수 있는지 계산해 둠.
(모든 블록들이 동일한 배열을 가지고, 한 개의 블록당 파라미터 개수를 계산하기가 쉬워서 가능했다)
Cost-efficient Retraining
LoRA 방식으로 pruned된 모델을 효율적으로 유지.

-> LoRA방식이 depth-pruned models의 성능을 저장할 수 있는 잠재력을 지님.
LoRA 기반 재학습은 single GPU에서 몇 시간 안에 가능.
예를 들어, 20% pruned된 (기존)7B 모델은 2시간 소요, 22GB VRAM
21% pruned된 (기존)13B 모델은 3시간 소요, 35GB VRAM
Experiments Settimgs
- Model
Testbed : LLaMA-7B, Vicuna-{7B, 13B}-v1.3 - Baseline
동일한 교정 데이터셋 D를 사용하여, width VS depth 두 pruning units을 비교.
1. Width pruning baseline methods (use official code for implementation)
- LLM Pruner는 MHA에서 어텐션 헤드를 제거하고, FFN에서 중간 뉴런을 제거하기 위해 Taylor 기반 중요도 metric을 사용. Local pruning은 검사된 그룹 전체에서 균일한 차원을 유지하면서 제거할만한 그룹을 선정하기 위해 사용된다. (맨 처음과 마지막 블록은 남겨두기)
이렇게 pruned된 모델과, 우리 모델(해당 논문)은 똑같이 LoRA 방식으로 재학습됨.
- FLAP 은 weight columns을 제거한 뒤 feature maps의 recoverability를 탐색하기 위해 변동 기반 중요도 metric 사용. 개별 모듈에 대해 widths가 달라지는 Global pruning이 적용됨. (표1에서 평균과 표준편차값 확인) 재학습 대신, 여분의 bias terms이 성능 복원을 위한 pruned feature maps에 더해짐.
- Wanda-sp 는 Wanda의 변형으로 structured pruning에 맞게 조정됨. 원래 metric은 가중치 크기와 input activation noem의 곱을 기반으로 하며, local reconstruction objective을 다루는 것을 목표로 한다고 해석할 수 있다. Wanda-sp는 서로 다른 모듈에 대해 공통된 dimension을 사용한다.
2) Data
BookCorpus에서 random하게 10개 문장 선정하여 pruning 단계에서 block level의 중요성 계산. 교정 데이터셋을 공평한 비교를 위해 똑같이 사용. LoRA 재학습 단계에서는 refined Alpaca의 50K samples가 사용됨.
3) Evaluation
Lm-evaluation-harness 패키지를 사용하여 일반 상식 추론 데이터셋에 대한 Zero-shot accuracy 측정.
(BoolQ, PIQA, HellaSwag, WinoGrande, ARC-easy, ARC-challenge 그리고 OpenbookQA)
WikiText2와 PTB에 대한 제로샷 PPL도 측정.
4) Latency and Throughput
Flexgen(2023 Sheng et al.,) 을 따름.
배치사이즈 (M), 출력 시퀀스 길이 (L)가 주어졌을 때, latency (T)는 주어진 prompt를 처리하고, ML 출력 토큰을 생성하기 위한 위한 시간을 나타낸다. 처리량은 M*L/T로 계산된다. 10 warm-up batches 후 20번 실행한 결과의 평균을 보고함.
5) Implementation
허깅페이스의 트랜스포머 라이브러리 사용.
pruning과 재학습 속도를 위해 NVIDIA A100 GPU 사용.
7B 크기 모델은 NVIDIA RTX3090에서도 돌아감.
추론 단계에서 xFormers-optimized attention과 advanced options을 제외한 기본 구성을 선택한다.
Conclusion
block pruning 방식을 소개함으로써, 우리는 LLM compression할 때 width와 depth의 영향을 심층 분석 한 결과,
우리의 방식은 one-shot으로 간단하면서도 zero-shot 성능과 비슷하다.
게다가 배치사이즈에 제한이 있는 상황에서 눈에띄는 추론 속도의 향상도 보였다.
uture works는 retraining 방법에 대한 연구와 full parameter updates 그리고 교정 데이터의 심층 분석과 더불어 knowledge distillation에 대한 연구가 필요하다
나의 생각
위 논문은 2024년도에 나온 논문임에도 불구하고 Llama를 사용했다.
더 최신 모델을 사용하지 않은 이유에 대한 언급이 없음이 의아하다.
inferece speed는 on-device에 탑재시킬 때에는 매우 중요한 포인트이다.
하지만, 문장의 길이가 길어질수록 출력 결과가 좋지 않다는 점은 큰 단점이다.
이때, 문장의 길이가 어느 정도로 길어졌을 때 결과가 좋지 않았는지에 대한 내용이 없어서 아쉽다.
Ablation Study가 잘 되어 있는 논문인 것 같다.
'AI > Language' 카테고리의 다른 글
| [Paper Review] A Survey on Multimodal Large Language Model (MLLM) (2) | 2024.08.22 |
|---|---|
| ROFORMER: ENHANCED TRANSFORMER WITH ROTARYPOSITION EMBEDDING (12) | 2024.07.23 |
| Transformer (7) | 2024.07.20 |
| [Paper Translate] A SURVEY ON RECENT ADVANCES IN NAMED ENTITYRECOGNITION (6) | 2024.07.16 |
| MCL-NER short breif (1) | 2024.07.03 |


