[Paper Translate] A SURVEY ON RECENT ADVANCES IN NAMED ENTITYRECOGNITION
- 계기
흔히 말하는 G2P 방법론에 대한 논문을 찾다가 발견한 논문이다.
음성인식에서 Named Entity Recognition을 하기 위해서 필요한 단계 중 하나라고 할 수 있겠다.
0. Abstract
명명된 개체 인식(NER)은 텍스트 내에서 실제 세계의 객체를 나타내는 부분 문자열을 추출하고 그것들의 유형(예: 인물 또는 조직에 대한 참조 여부)을 결정하는 것을 목표로 합니다. 이 조사에서는 먼저 최근 인기 있는 접근 방법을 개괄적으로 소개하고, 다른 조사에서는 많이 다루지 않은 그래프 기반 및 트랜스포머 기반 방법(대형 언어 모델 포함)을 살펴봅니다. 두 번째로, 주석이 적은 데이터셋을 대상으로 설계된 방법에 집중합니다. 세 번째로, 다양한 특성을 가진 데이터셋(도메인, 크기, 클래스 수 등)에 대해 주요 NER 구현의 성능을 평가합니다. 이를 통해 함께 고려되지 않았던 알고리즘을 깊이 있게 비교합니다. 우리의 실험은 데이터셋의 특성이 비교하는 방법의 동작에 어떻게 영향을 미치는지에 대한 통찰을 제공합니다.
1. Introduction
명명된 개체 인식(NER)은 컴퓨터 과학 및 자연어 처리(NLP) 분야로, 비구조화된 텍스트에서 명명된 항목을 식별하고 분류하는 작업을 다룹니다. 여기서 명명된 항목은 사람, 장소, 조직과 같은 사전 정의된 의미적 유형에 속합니다 [Grishman and Sundheim, 1996a]. NER은 오늘날 기계 번역 [Babych and Hartley, 2003], 질문-응답 [Mollá et al., 2006], 정보 검색 [Guo et al., 2009] 등의 분야에서 중요한 구성 요소입니다.
여러 NER 시스템이 개발되었으며, 특히 영어뿐만 아니라 중국어 [Liu et al., 2022], 프랑스어 [Mikheev et al., 1999] 등 다양한 언어를 지원합니다. 초기 NER 시스템은 수작업으로 작성된 규칙, 사전, 철자 기능을 기반으로 하는 알고리즘을 사용했습니다 [Rau, 1991]. 이후에는 기계 학습 [Nadeau and Sekine, 2007], 신경망 [Collobert, 2011], 트랜스포머 [Labusch et al., 2019a]를 기반으로 한 알고리즘을 사용하는 시스템이 개발되었습니다.
여러 NER 조사 연구가 출판되었습니다. 예를 들어, [Nadeau and Sekine, 2007; Shaalan, 2014]에서는 규칙 기반 NER 시스템부터 기계 학습 기반 시스템까지의 방법론을 개괄적으로 소개합니다. [Goulart et al., 2011]은 2007-2009년 기간 동안 생물 의학 텍스트와 관련된 주요 연구를 분석합니다. [Marrero et al., 2013]는 이론적 및 실용적 관점에서 NER 연구를 요약합니다. 초기 신경망 기반 NER 연구는 [Sharnagat, 2014]에 제공되어 있습니다. 심층 학습 방법은 [Li et al., 2020a]에서 심도 있게 다루어지지만, 트랜스포머의 사용은 당시 연구 시점에서 제한적이었기 때문에 다루지 않았습니다.
트랜스포머 기반 방법을 포함한 조사는 문헌에서 거의 찾아볼 수 없습니다. 최근 몇몇 연구는 신경망과 트랜스포머 기반 방법을 포함하고 있지만 [Li et al., 2022], 최신 대형 언어 모델(LLM) 및 그래프 기반 NER을 포함하지 않아 완전하지 않습니다. [Wang et al., 2022] 연구는 중첩된 명명된 개체를 위한 그래프 기반 방법에 초점을 맞추지만, 평면 명명된 개체는 다루지 않습니다. 또한, 트랜스포머를 언급하지 않은 [Li et al., 2020a]을 제외하고, NER에 사용되는 도구를 다루지 않습니다. 도구는 실용적인 관심사의 핵심 구성 요소이므로, 여기서는 저자들이 최근 트랜스포머 기반 방법과 함께 이러한 도구를 포괄적으로 조사합니다.
또한, 소규모 데이터셋에서 훈련하도록 설계된 방법에 중점을 둡니다. 이러한 방법은 특정 유형의 개체를 검색하고 주석을 다는 데 비용이 많이 드는 경우에 적합합니다.
이 논문의 개요는 다음과 같습니다. 먼저 NER 작업을 정의하고 그 응용 사례를 제시합니다. 그런 다음 이 분야에서 개발된 주요 연구 접근법을 설명합니다(섹션 4). 특히 대형 언어 모델(LLM)과 그래프 기반 접근법에 중점을 둡니다. 소규모 주석 데이터가 있는 상황을 위한 방법은 섹션 5에 제시됩니다. 섹션 6에서는 사전 훈련된 모델을 위한 도구를 개괄적으로 설명합니다. NER에서 사용되는 평가 방식(섹션 7)을 설명한 후, 연구 커뮤니티에 유용할 수 있는 다양한 분야의 코퍼스를 소개합니다(섹션 8). 섹션 9에서는 비교를 위해 다섯 가지 인기 있는 프레임워크의 최신 버전을 선택된 데이터셋에 적용합니다. 마지막으로 결론과 전망을 섹션 10에서 제시합니다.
2. 작업 정의
NER(명명된 개체 인식)은 텍스트 내에서 명명된 개체를 식별하고 분류하는 NLP(자연어 처리)의 하위 작업입니다. 명명된 개체는 사람, 조직, 장소, 날짜, 수량, 생물 의학 도메인에서는 유전자 및 단백질 이름 등 실제 세계의 객체를 지칭하는 특정 단어 또는 구문입니다. NER의 목표는 이러한 개체를 찾아 미리 정의된 범주로 분류하는 것입니다.
공식적인 문맥에서, 주어진 토큰 시퀀스 T=(t1,t2,...,tN) 에 대해, NER은 튜플 (Is,Ie,ℓ)의 컬렉션을 생성합니다. 여기서 s 와 e 는 [1, N] 범위 내의 정수이며, Is 와 Ie 는 각각 명명된 개체 언급의 시작과 끝 인덱스를 나타내며, 은 미리 정의된 범주 집합에서 개체의 유형을 나타냅니다. 예를 들어, "Barack Obama was born in Honolulu."라는 문장에서 NER은 "Barack Obama"를 사람의 이름으로, "Honolulu"를 장소로 식별합니다. 이는 그림 1에 예시되어 있습니다.
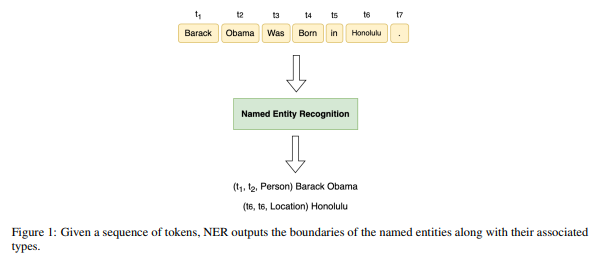
3. NER의 응용 분야
이 섹션에서는 NER(명명된 개체 인식)의 몇 가지 응용 사례를 소개합니다.
- 정보 추출: NER은 비구조화된 텍스트에서 구조화된 데이터를 추출하는 데 사용할 수 있습니다 [Weston et al., 2019]. 예를 들어, 사람, 조직, 장소의 이름을 추출할 수 있습니다.
- 정보 검색: 정보 검색 맥락에서 NER을 사용하면 검색 결과를 향상시킬 수 있습니다 [Banerjee et al., 2019]. 이는 검색 쿼리와 검색 결과 내에서 관련된 명명된 개체를 식별함으로써 이루어집니다.
- 문서 요약: NER을 문서 요약 과정에 통합하면 생성된 요약문의 품질과 관련성을 높일 수 있습니다. 주요 개체를 식별하고 분류함으로써 요약문이 이러한 개체와 관련된 중요한 정보를 포착하도록 합니다 [Roha et al., 2023].
- 소셜 미디어 모니터링: 소셜 미디어 모니터링과 통합된 NER은 기업이 브랜드 및 사람과 같은 개체의 언급을 자동으로 식별하고 분류할 수 있도록 합니다. 이는 브랜드 가시성 추적, 감정 분석, 경쟁자 통찰, 위기 관리에 도움이 됩니다. 또한 트렌드 파악, 캠페인 효과 평가, 인플루언서 마케팅 활용에도 도움이 됩니다 [Sufi et al., 2022].
- 가상 비서: NER은 사용자 입력 내에서 개체를 식별하여 가상 비서가 문맥을 이해하고 맞춤형 응답을 제공할 수 있도록 합니다 [Park et al., 2023]. 예를 들어, 사용자가 특정 위치의 날씨를 묻는 경우 NER은 위치 개체를 추출하여 가상 비서가 관련 응답을 제공할 수 있게 합니다.
- 명명된 개체의 중의성 해소: NER은 동일한 이름을 가진 개체를 구별하는 데 도움이 될 수 있습니다 [Al-Qawasmeh et al., 2016]. 예를 들어, "Apple"은 회사 또는 과일을 의미할 수 있으며, NER은 주변 문맥을 기반으로 올바른 해석을 결정할 수 있습니다.
- 질문 응답: NER은 특정 개체를 지목하는 질문에 답하는 데 중요한 역할을 할 수 있습니다 [Mollá et al., 2006]. 예를 들어, "When did Steve Jobs die?"라는 질문에서 NER은 "Steve Jobs"를 인물로 식별하고 사망 날짜를 추출할 수 있습니다.
- 언어 번역: NER은 명명된 개체를 보존함으로써 기계 번역의 정확성을 향상시키는 데 도움이 될 수 있습니다 [Li et al., 2020b].
참고 문헌
- Weston, D., & Others. (2019). Structured data extraction from unstructured text.
- Banerjee, P., & Others. (2019). Enhancing search outcomes with NER.
- Roha, S., & Others. (2023). Improving document summarization with NER.
- Sufi, R., & Others. (2022). Social media monitoring with NER.
- Park, J., & Others. (2023). Virtual assistants and NER.
- Al-Qawasmeh, M., & Others. (2016). Disambiguating named entities.
- Mollá, D., & Others. (2006). Question answering with NER.
- Li, X., & Others. (2020b). Improving machine translation with NER.
4. 방법론
이 섹션에서는 NER(명명된 개체 인식)을 위해 사용된 다양한 접근 방법을 탐구합니다. 이러한 접근 방법의 개요는 그림 2에 나와 있습니다.
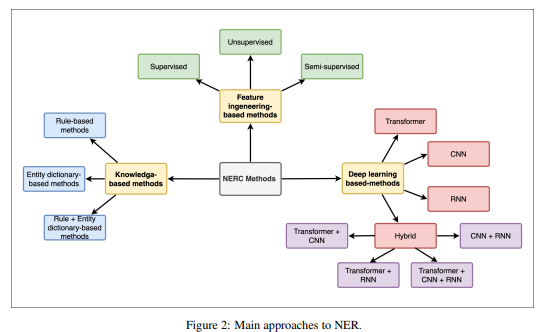
4.1 지식 기반 방법
지식 기반 접근법은 언어학 분야에서 등장했습니다. 예를 들어, Borkowski [1966]는 회사 이름을 감지하기 위해 대문자와 같은 지표를 사용하는 규칙 기반 리스트를 활용하는 알고리즘을 도입했습니다. 어휘 표시는 명명된 개체와 인접하여 그 존재를 드러내는 요소입니다(예: 이름 앞의 Mr. 또는 Ms.). 여기에는 프랑스어 명명된 개체를 인식하기 위해 만든 CasEN 변환기 계단식 [Maurel et al., 2011]을 예로 들 수 있습니다.
지식 기반 방법은 주석이 달린 데이터를 필요로 하지 않으며, 주로 규칙과 사전, 어휘 자원 및 도메인별 지식에 의존합니다 [Sekine and Nobata, 2004; Etzioni et al., 2005a]. 이 접근법은 다음의 세 가지 구성 요소로 이루어져 있습니다:
- 명명된 개체를 추출하기 위한 규칙 집합
- 선택적인 개체 사전 집합
- 입력 텍스트에 구성 요소 (1)과 (2)를 적용하는 추출 엔진
이러한 접근법은 도메인 전문가가 어휘 표시 [Zhang and Elhadad, 2013] 또는 개체 사전 [Etzioni et al., 2005a; Sekine and Nobata, 2004]을 사용하여 많은 수의 규칙을 제공해야 합니다.
개체 사전은 특정 응용 도메인 내에서 가장 일반적으로 발생하는 개체를 수집합니다. 예를 들어, ProMiner 시스템 [Hanisch et al., 2005]은 생물 의학 텍스트에서 유전자 및 단백질 이름을 식별하는 문제를 다룹니다. 이 시스템은 규칙 기반 접근법과 동의어 사전을 사용하여 생물 의학 텍스트에서 잠재적 이름 발생을 감지합니다. 이 시스템은 BioCreAtIvE 대회에서 테스트되어 유망한 결과를 얻었습니다.
Quimbaya et al. [2016]는 전자 건강 기록에서 개체 사전을 중심으로 한 방법을 소개했습니다. 실험 결과에 따르면 이 접근법은 정밀도에 큰 영향을 미치지 않으면서도 재현율을 향상시킵니다. 이 방법군의 경우, 도메인 및 언어별 규칙과 불완전한 사전 때문에 정밀도가 일반적으로 높고 재현율이 낮습니다. 또한, 새로운 규칙과 사전을 통합하는 데 비용이 많이 듭니다.
4.2 특징 엔지니어링 기반 방법
특징 엔지니어링 기반 방법은 수작업으로 규칙을 만드는 대신, 데이터로부터 명명된 개체를 자동으로 추출하는 원리에 기반합니다. 이러한 기술은 크게 세 가지 주요 그룹으로 나눌 수 있습니다: 비지도 학습 방법, 지도 학습 방법, 반지도 학습 방법.
4.2.1 비지도 학습 방법
비지도 학습 방법은 사전 데이터 주석이 필요하지 않습니다. 다양한 접근법이 존재하며 주로 데이터의 유사성에 기반합니다. 이러한 방법의 핵심 아이디어는 공통 속성을 기반으로 신탁마를 그룹화하는 것입니다.
- Shinyama and Sekine (2004a): 이 논문에서는 단어의 분포를 활용하여 명명된 개체를 추출하는 방법을 소개합니다. 저자들은 명명된 개체가 여러 뉴스 기사에 함께 나타나는 경향이 있다는 관찰에 기초합니다.
- Bonnefoy et al. (2011): 이 논문에서는 엔티티와 엔티티 유형에 연결된 문서에서 단어 분포를 비교하여 의미적 근접 점수를 계산합니다.
- Nadeau et al. (2006): 이 논문에서는 사전을 구축하고 명명된 개체의 모호성을 해결하기 위한 비지도 시스템을 소개합니다. 이전 연구들에 영감을 받아, 추출된 사전을 공개적으로 접근 가능한 사전과 결합하여 우수한 성능을 발휘합니다 [Etzioni et al., 2005b].
4.2.2 반지도 학습 방법
반지도 학습 방법은 라벨이 있는 데이터와 없는 데이터를 결합하여 모델 성능을 향상시킵니다. 라벨이 있는 데이터에 의존하는 전통적인 지도 접근법과 달리, 반지도 학습 방법은 라벨이 없는 데이터에서 사용할 수 있는 추가 정보를 활용하여 NER 시스템의 성능을 향상시킵니다.
- Collins and Singer (1999): 단순한 일곱 가지 규칙 세트와 라벨이 없는 데이터만으로도 효과적인 감독을 달성할 수 있음을 보여줍니다.
- Co-training (Kozareva et al., 2005): 여러 분류기를 다른 데이터 뷰에서 훈련시키고, 반복적으로 라벨이 없는 인스턴스를 라벨링하여 보다 강력한 모델을 구축합니다.
- Self-training (Gao et al., 2021): 초기 모델을 라벨이 있는 데이터로 훈련시키고, 이를 사용하여 라벨이 없는 데이터에 대해 라벨을 예측합니다. 가장 확신이 높은 예측을 라벨이 있는 데이터에 추가하고, 이 과정을 반복합니다.
반지도 학습 방법은 수작업으로 라벨링된 데이터셋에 대한 의존성을 줄이고, 저자원 시나리오에서 성능을 향상시키는 등 여러 가지 이점을 제공합니다. 그러나 초기 라벨이 있는 데이터에서의 잠재적인 오류 전파와 라벨이 없는 데이터의 노이즈 또는 잘못된 예측을 신중하게 처리해야 하는 등의 과제도 존재합니다. 그러나 신중하게 적용하면, 반지도 학습 기술은 NER 성능을 크게 향상시키고, 라벨이 있는 데이터가 제한적이거나 생산 비용이 높은 실제 문제를 해결할 수 있습니다.
4.2.3 지도 학습 방법
지도 학습 모델은 주석이 달린 데이터로부터 규칙을 학습하며, 이 과정에서 인간의 개입이 필요합니다. 이 주석이 달린 샘플들은 학습 과정 동안 모델에게 지침을 제공합니다. 학습 방법을 사용하여 모델을 훈련하고 명명된 개체의 특성을 인식하도록 합니다. 이후 학습 시스템은 이 지식을 일반화하여 새로운 문서에서 명명된 개체를 추출할 수 있는 모델을 생성합니다. 이러한 방법의 효과는 훈련에 사용되는 주석 데이터의 양과 질에 따라 향상됩니다.
NER 작업은 두 가지 하위 작업으로 볼 수 있습니다. 즉, 분류와 시퀀스 라벨링입니다. 목표는 주석이 달린 데이터에서 학습한 주석 체계를 재현하는 것입니다. 이 범주에서 가장 일반적인 알고리즘이나 모델은 다음과 같습니다:
- 히든 마르코프 모델(HMM) [Morwal et al., 2012; Bikel et al., 1999]
- 최대 엔트로피 모델(ME) [Borthwick, 1999; Lin et al., 2004]
- 서포트 벡터 머신(SVM) [Isozaki and Kazawa, 2002; Makino et al., 2002]
- 조건부 랜덤 필드(CRF) [McCallum and Li, 2003; Settles, 2004a]
히든 마르코프 모델(HMM)
HMM은 모델링되는 시스템이 마르코프 과정이라고 가정하는 통계적 모델입니다. NER 문맥에서, HMM은 토큰 시퀀스 내에서 명명된 개체를 식별하고 분류하는 데 사용됩니다. 이 모델에서 관찰된 토큰은 가시 상태를 나타내고, 다양한 엔티티 라벨은 숨겨진 상태로 취급됩니다. 모델은 관찰된 토큰이 현재 숨겨진 상태에만 의존한다고 가정하며, 관찰된 토큰이 주어졌을 때 가장 가능성이 높은 명명된 개체 라벨 시퀀스를 추론하는 데 사용할 수 있습니다. HMM은 다음과 같은 다섯 가지 매개변수로 설명됩니다:
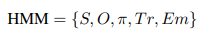
여기서 S는 숨겨진 상태(엔티티 라벨)의 수를, O는 관찰(토큰)의 수를, π는 초기 상태 확률 분포를, Tr는 전이 확률 행렬을, Em은 방출 확률 행렬을 나타냅니다.
NER 문제는 HMM 문제로 변환될 수 있으며 다음과 같이 정의됩니다:
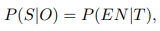
이는 토큰 시퀀스 T가 주어졌을 때 명명된 개체 시퀀스(EN)를 얻을 확률이 관찰된 토큰 O이 주어졌을 때 숨겨진 상태 시퀀스 S를 얻을 확률을 계산하는 것과 같음을 의미합니다.
최대 엔트로피 모델(ME)
ME 모델은 NER을 포함한 다양한 NLP 작업에 사용되는 통계적 모델링 접근법입니다. 이 모델의 기본 개념은 잠재적인 결과를 포함하는 확률 분포를 식별하고, 관찰된 제약 조건을 준수하면서 엔트로피를 최적화하는 것입니다. NER 문맥에서, ME 모델은 주어진 토큰의 명명된 개체 라벨을 예측하기 위해 훈련될 수 있습니다.
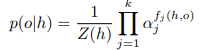
여기서 o는 결과, 는 문맥, Z(h)는 정규화 함수입니다.
조건부 랜덤 필드(CRF)
CRF는 시퀀스를 라벨링하는 데 사용되는 모델로, 인접 항목이 서로의 라벨에 영향을 미칠 수 있다고 가정하여 NER에 적합합니다. CRF는 로컬 및 글로벌 정보를 통합하여 인접 토큰의 라벨을 고려해 엔티티 라벨을 예측할 수 있습니다.
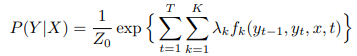
여기서 Z0는 모든 가능한 상태 시퀀스(라벨)의 정규화 인자, fk는 관찰과 관련된 라벨 조합의 발생을 나타내는 특성 함수, 는 모델 매개변수입니다.
서포트 벡터 머신(SVM)
SVM은 주로 분류 작업에 사용되는 기계 학습 알고리즘으로, NER에도 적절한 특징 엔지니어링과 함께 효과적으로 적용될 수 있습니다.
이러한 지도 학습 방법은 주석이 달린 데이터의 양과 질에 따라 성능이 크게 좌우됩니다. 적절한 적용과 특징 엔지니어링을 통해 NER 성능을 크게 향상시킬 수 있습니다.
4.3 딥러닝 기반 방법
NER과 딥러닝의 풍경은 CNNs, RNNs 및 이들의 혼합 결합을 포함하는 가장 일반적인 방법론과 함께 더욱 발전했습니다. 또한 이러한 딥러닝 아키텍처는 종종 SVM 또는 CRF와 같은 다른 지도 학습 알고리즘과 결합됩니다. Collobert [2011]는 NER에 딥러닝 기술을 채택한 선구적인 역할을 했습니다. 그들의 연구는 NER뿐만 아니라 의미역 표시, 품사 태깅, 청킹과 같은 다른 NLP 작업에서도 CNN의 적용을 보여주었습니다. 중요한 점은, 이러한 작업들이 수동으로 설계된 특징에 의존하지 않고 자동으로 수행되었다는 것입니다. 이는 딥 뉴럴 네트워크가 처음으로 이러한 작업에 활용된 중대한 순간을 의미했습니다.
딥러닝 기반 접근법의 전반적인 구조는 보통 세 가지 기본 단계를 포함합니다(그림 4 참조):
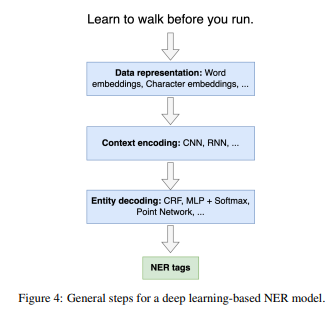
- 데이터 표현
- 문맥 인코딩
- 엔티티 디코딩
이 단계들은 다음 섹션에서 자세히 설명됩니다.
데이터 표현
데이터 표현 단계는 원시 텍스트 데이터를 모델이 이해할 수 있는 형태로 변환하는 과정입니다. 이 단계에서는 주로 단어 임베딩을 사용하며, 대표적인 기법으로는 Word2Vec, GloVe, 그리고 최근의 BERT와 같은 컨텍스트를 고려한 임베딩 방법이 있습니다. 이러한 임베딩 기법은 단어를 고차원 공간에서 벡터로 변환하여 의미적 유사도를 반영합니다.
문맥 인코딩
문맥 인코딩 단계에서는 입력 시퀀스의 문맥 정보를 캡처하는 작업이 이루어집니다. RNN(특히 LSTM이나 GRU)은 순차 데이터를 처리하고 이전 시점의 정보를 현재 시점으로 전달하는 데 강점을 가지고 있습니다. CNN은 고정된 크기의 윈도우를 통해 지역적 문맥을 캡처하는 데 유리합니다. 최근에는 트랜스포머 아키텍처가 문맥 인코딩에 널리 사용되고 있으며, 이는 멀티-헤드 셀프 어텐션 메커니즘을 통해 글로벌 문맥 정보를 효율적으로 캡처할 수 있습니다.
엔티티 디코딩
엔티티 디코딩 단계에서는 문맥 인코딩에서 생성된 표현을 기반으로 명명된 개체를 식별하고 분류합니다. CRF는 출력 레이어에서 종종 사용되며, 이는 시퀀스 레이블링 작업에서 각 토큰의 라벨이 인접 토큰의 라벨에 영향을 받을 수 있도록 합니다. 이 단계는 모델이 최종적으로 명명된 개체를 올바르게 식별하고 분류할 수 있도록 돕습니다.
주요 연구 사례
- Collobert et al. (2011): CNN을 활용하여 NER을 포함한 다양한 NLP 작업을 자동으로 처리하는 방법을 제안하였으며, 이는 수동으로 설계된 특징 없이 수행되었습니다.
- Lample et al. (2016): LSTM과 CRF를 결합하여 NER의 성능을 향상시킨 연구를 발표하였습니다.
- Devlin et al. (2019): 트랜스포머 아키텍처를 사용한 BERT 모델을 소개하여 NER을 포함한 여러 NLP 작업에서 뛰어난 성능을 보여주었습니다.
이러한 딥러닝 기반 접근법은 NER 작업의 정확도를 크게 향상시켰으며, 특히 대규모 데이터셋과 결합할 때 그 효과가 극대화됩니다.
4.3.1 데이터 표현
NER은 데이터를 기계가 이해할 수 있는 형태로 표현해야 합니다. 텍스트 임베딩은 이 요구를 충족시키기 위해 사용될 수 있습니다. 여러 텍스트 임베딩 기술이 존재하며, 이를 두 가지 주요 범주로 나눌 수 있습니다: 단어 임베딩과 문자 임베딩.
단어 임베딩
단어 임베딩은 단어를 고차원 공간에서 벡터 표현으로 변환하는 단어 표현 방식입니다. 이러한 표현은 주어진 말뭉치에서 주변 단어를 기반으로 단어의 의미와 문맥을 포착합니다. 주목할 만한 기법으로는 One-Hot 인코딩, TF-IDF [Ramos et al., 2003], Word2vec [Mikolov et al., 2013], GloVe [Pennington et al., 2014], fastText [Bojanowski et al., 2016], 그리고 최근의 GPT [Radford et al., 2018] 등이 있습니다.
전통적인 단어 표현, 예를 들어 One-Hot 인코딩은 각 단어를 희소한 이진 벡터로 나타내며, 어휘에서 해당 단어의 존재를 나타내기 위해 하나의 요소만 1로 설정됩니다. NER에서 One-Hot 인코딩의 사용은 소셜 미디어 메시징 애플리케이션에서 자동으로 학습 데이터를 구성하는 것을 포함합니다 [Lee and Ko, 2020].
TF-IDF 가중치는 말뭉치에 비해 문서 내에서 단어의 중요도를 측정하는 데 사용됩니다. 용어 빈도(TF) 구성 요소는 특정 문서에서 단어가 얼마나 자주 나타나는지 평가하고, 역문서 빈도(IDF) 구성 요소는 전체 말뭉치에서 단어의 희귀성을 측정합니다. TF와 IDF를 곱하여 TF-IDF는 문서에서 중요한 단어를 강조합니다. NER에서 TF-IDF는 특징 표현 방법으로 사용할 수 있습니다 [Karaa, 2011].
단어 임베딩은 일반적으로 Word2Vec, GloVe 및 fastText와 같은 비지도 학습 기법을 사용하여 학습됩니다. 이러한 방법은 대량의 텍스트 데이터를 처리하고 단어 간의 의미적 유사성과 구문 관계를 포착하는 단어 표현을 학습합니다. 여러 연구들은 NER을 위해 단어 임베딩을 사용합니다 [Collobert et al., 2011; Huang et al., 2015; Ma and Hovy, 2016; Lample et al., 2016].
문자 임베딩
문자 임베딩은 단어의 내부 구조를 문자 수준에서 포착하는 단어 표현 방식입니다. 전통적인 단어 임베딩처럼 단어를 벡터로 나타내는 대신, 문자 임베딩은 각 단어를 그 구성 문자들을 나타내는 벡터 시퀀스로 나타냅니다. 문자 임베딩을 생성하는 과정은 각 단어를 문자로 분해하고, 각 문자를 벡터로 나타내는 것입니다. 이러한 벡터는 CNN 아키텍처를 활용하여 단어의 표현을 형성합니다.
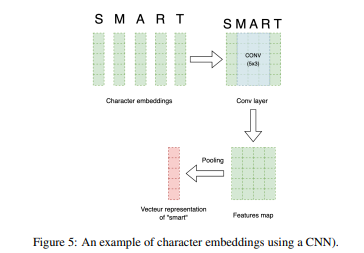
문자 임베딩은 철자 변화를 포착하여 명명된 개체의 존재를 드러낼 수 있습니다. 학습 단계에서 만나지 않은 단어, 즉 어휘 외 단어를 다른 문자 벡터를 결합하여 표현할 수 있습니다.
CNN 기반 문자 임베딩은 문자 시퀀스를 이미지로 취급하여 CNN 필터를 통해 의미 있는 특징을 추출합니다. BiLSTM 기반 문자 임베딩은 양방향 LSTM 네트워크를 사용하여 문자 시퀀스의 문맥 정보를 포착합니다 [Ma and Hovy, 2016; Peters et al., 2017, 2018b]. Lample et al. (2016)의 연구는 순환 모델이 접미사를 접두사보다 더 잘 인코딩하는 경향이 있음을 발견했으며, 따라서 접두사를 더 잘 포착하기 위해 Bi-LSTM을 권장합니다.
이와 같은 데이터 표현 방법은 NER 작업의 성능을 향상시키는 데 중요한 역할을 합니다.
4.3.2 문맥 인코딩
엔티티 인식을 개선하기 위해 문맥 인코딩은 단어의 문맥 정보를 캡처하는 NER 시스템의 중요한 측면입니다. 문맥 인코딩 기술은 단어를 주변 문맥에서 표현하여 인접 단어 간의 종속성과 관계를 고려합니다. 단어, 문자 또는 두 가지의 조합을 기반으로 한 텍스트 임베딩을 사용하여 특징 벡터를 얻습니다. 이 섹션에서는 CNN 및 RNN과 같은 인기 있는 문맥 인코더 아키텍처를 소개합니다. 트랜스포머와 같은 다른 모델은 별도의 섹션에서 다룹니다.
CNN (Convolutional Neural Networks)
CNN 모델은 처음에는 이미지 처리에 사용되었습니다 [O'Shea and Nash, 2015]. 필터를 사용하여 패턴과 특징을 감지합니다. 이러한 사용은 NER과 같은 NLP 작업으로 성공적으로 확장되었습니다. 여기서 입력 텍스트는 일반적으로 단어 임베딩이나 문자 시퀀스로 표현됩니다. CNN은 문맥 정보를 캡처하고 로컬 패턴을 인식하는 데 사용됩니다. 컨볼루션 레이어는 입력 시퀀스를 슬라이드하면서 여러 위치에서 다양한 언어적 패턴을 감지합니다. 이러한 필터는 접미사, 접두사 및 명명된 개체를 나타내는 단어 조합과 같은 일반적인 패턴을 인식하도록 학습합니다.
여러 저자들이 NER 작업을 위해 CNN을 사용했습니다. Collobert et al. [2011]은 문장 기반 네트워크를 제안하여 전체 문장을 고려하여 단어를 태그합니다. 각 단어는 벡터로 표현되고, 컨볼루션 레이어는 각 단어 주위의 로컬 특징을 생성합니다. 전역 특징 벡터는 이러한 로컬 특징을 결합하여 문장 길이에 관계없이 고정된 차원을 갖습니다. 전역 특징은 태그 디코더로 전달되어 태그를 예측합니다. [Gui et al., 2019]은 사전과 재고려 메커니즘을 사용하여 중국어 NER을 위한 CNN 접근 방식을 제안했습니다. 이 메커니즘은 네트워크가 고급 피드백을 특징 추출에 통합하여 결정을 재평가할 수 있도록 합니다. 저자들은 이 방법이 문자를 모델링하고 잠재적 단어 충돌을 고급 특징을 반복적으로 정제하여 해결할 수 있음을 보여주었습니다.
RNN (Recurrent Neural Networks)
RNN은 순차 데이터를 처리하도록 설계되었으며, 단어의 문맥이 정확한 라벨링에 중요한 작업에 적합합니다 [Sherstinsky, 2020]. NER 문맥에서 입력 텍스트는 임베딩 시퀀스로 표현되며, 각 단어는 한 번에 하나씩 RNN에 입력됩니다. RNN은 이전 단어의 정보를 캡처하는 숨겨진 상태를 유지합니다. 이 숨겨진 상태는 RNN이 각 단어를 처리할 때마다 업데이트되어 중요한 정보를 기억할 수 있게 합니다. RNN의 과제 중 하나는 장기 종속성을 캡처하는 능력을 제한하는 기울기 소실 문제입니다. 이를 해결하기 위해 LSTM [Sherstinsky, 2020]과 GRU [Chung et al., 2014]와 같은 RNN 변형이 도입되었습니다. LSTM과 GRU 네트워크는 장기 시퀀스에서 정보를 더 효과적으로 유지하고 업데이트할 수 있는 게이트 메커니즘을 사용하여 NER 작업에 더 적합합니다.
Huang et al. [2015]은 NER을 위해 LSTM 모델을 제안하고, CRF 레이어를 태그 디코더로 통합하여 성능을 향상시켰음을 보여주었습니다. Chalapathy et al. [2016]은 약물 NER에, Zhang and Yang [2018]은 중국어 NER에 유사한 시스템을 적용했습니다. Bi-LSTM 아키텍처를 기반으로 한 RNN은 여러 연구에서 사용되었습니다 [Ma and Hovy, 2016; Lample et al., 2016].
이와 같은 문맥 인코딩 방법은 NER 시스템의 성능을 향상시키는 데 중요한 역할을 하며, 특히 단어 간의 복잡한 관계와 종속성을 캡처할 수 있습니다.
4.3.3 엔티티 디코딩
태그 디코더 아키텍처는 주어진 시퀀스의 각 단어에 대해 엔티티 라벨을 예측하는 NER 시스템에서 중요한 역할을 합니다. 여러 태그 디코더 아키텍처가 제안되었으며, 각각의 강점과 NER 시나리오에 대한 적합성이 다릅니다. NER을 위한 일반적인 태그 디코더 아키텍처로는 CRF, 다층 퍼셉트론(MLP), 포인터 네트워크 [Vinyals et al., 2015]가 있습니다. [Lample et al., 2016; Ma and Hovy, 2016]의 연구는 엔티티 디코딩에 CRF를 사용하는 것이 NER에서 개선된 결과를 가져온다고 보여주었습니다. 많은 딥러닝 기반 NER 모델이 BiLSTM [Luo et al., 2018; Lin et al., 2019] 또는 CNN 레이어 [Knobelreiter et al., 2017; Feng et al., 2020] 위에 CRF 레이어를 태그 디코더로 사용합니다.
NER은 일반적으로 시퀀스 라벨링 작업으로 접근하며, 목표는 개별 단어에 엔티티 태그를 할당하는 것입니다. 이를 달성하는 한 가지 간단한 방법은 MLP와 소프트맥스 레이어를 태그 디코더로 사용하는 것입니다. 이 방법은 시퀀스 라벨링 작업을 다중 클래스 분류 문제로 변환하여 각 토큰의 태그를 독립적으로 예측합니다 [Gallo et al., 2008; Lin et al., 2019].
한편, 포인터 네트워크는 대규모 출력 공간을 가진 작업(예: 시퀀스-투-시퀀스 작업)을 위한 RNN입니다. 주요 아이디어는 모델이 고정된 어휘 대신 입력 시퀀스의 요소를 직접 가리킬 수 있도록 하는 것입니다. 이 유연성은 훈련 데이터에 없는 항목이나 알 수 없는 출력 길이를 포함하는 출력 시퀀스를 처리할 때 유용합니다. 이 접근법은 NER과 같은 많은 NLP 작업에서 성공을 거두었습니다 [Zhai et al., 2017].
4.4 트랜스포머 기반 언어 모델
언어 모델은 NLP의 핵심 구성 요소입니다. 이들은 방대한 데이터 세트를 학습하여 자연어 텍스트를 처리, 분석 및 생성하는 방법을 개발하는 데 사용됩니다 [OCDE, 2023]. 최근의 이러한 방법들은 트랜스포머 아키텍처를 기반으로 구축되었습니다.
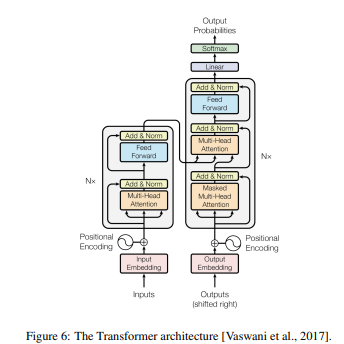
트랜스포머 [Vaswani et al., 2017]는 긴 거리 종속성을 쉽게 처리하면서 시퀀스-투-시퀀스 작업을 해결하는 것을 목표로 하는 대규모 말뭉치에서 사전 학습된 신경망입니다. 일반적으로 트랜스포머 모델은 인코더-디코더 아키텍처를 기반으로 합니다. 인코더의 역할은 출력 시퀀스를 컨텍스트 벡터라는 고정 길이 벡터로 인코딩한 후 디코더에 입력하는 것입니다. 디코더는 인코더 출력과 이전 시점의 디코더 출력을 읽어 출력 시퀀스를 생성합니다.
트랜스포머 기반 모델은 두 가지 주요 그룹으로 나뉩니다: 인코더 기반 모델과 디코더 기반 모델. 여기에서는 인코더 기반 트랜스포머 모델에 중점을 두고, 디코더 또는 둘의 조합을 기반으로 한 모델, LLMs는 다음 섹션에서 다룹니다.
트랜스포머 기반 인코더 모델은 NER을 포함한 NLP에 큰 영향을 미쳤습니다. 이들은 NER을 위해 직접적으로 문맥 인코더로 사용되거나, CRF 또는 LSTM과 같은 다른 모델에 입력을 제공하는 데 사용될 수 있습니다. 예를 들어, BERT [Devlin et al., 2018]는 독일어를 위한 문자 표현으로 사용되었습니다 [Schweter and Baiter, 2019]. 다른 연구자들은 BERT를 분류기로 사용하여 다른 Bi-LSTM-CRF 기반 방법보다 우수한 성능을 보였습니다 [Labusch et al., 2019b; Riedl and Padó, 2018]. BERT와 RNN을 결합한 여러 하이브리드 작업은 BERT가 텍스트의 기본 특징을 추출하고, BiLSTM이 텍스트의 문맥 표현을 학습하며, Multi-Headed Attention Mechanism(MHATT)이 챕터 수준의 특징을 추출하는 방식입니다 [Liu et al., 2021a].
BERT의 다양한 변형(예: DistilBERT [Sanh et al., 2019], Roberta [Liu et al., 2019a])은 NER 작업에서 매우 효과적이고 널리 채택되었습니다. DistilBERT는 BERT의 지식을 증류하여 크기와 계산 속도 면에서 훨씬 작은 버전입니다. Roberta는 더 큰 사전 학습 말뭉치를 사용하고, 마스크된 언어 모델이라는 새로운 학습 접근 방식을 사용하여 더 깊은 문맥 임베딩과 표현을 캡처합니다.
BERT 모델의 크기와 자원 집약적인 특성으로 인해 배포 환경에서의 도전 과제를 탐구한 연구도 있습니다 [Abadeer, 2020]. 연구자들은 DistilBERT를 의료 텍스트에 맞게 미세 조정하여 보호 건강 정보(PHI)와 의료 개념(MC)을 포함하는 NER 작업을 수행했습니다. DistilBERT는 거의 동일한 F1 점수를 기록하면서도 실행 시간과 디스크 공간에서 절반 정도를 소비합니다. 복잡한 다국어 NER 문제를 해결하기 위해 기본 XLM-Roberta 모델을 여러 언어의 데이터셋에서 정제하는 접근법도 시도되었습니다 [Mehta and Varma, 2023].
4.5 대형 언어 모델 기반 방법
대형 언어 모델(LLMs)은 번역, 요약, 분류 및 콘텐츠 생성 등 다양한 작업을 수행할 수 있는 새로운 범주의 딥러닝 모델을 나타냅니다. 이러한 모델은 수십억 개의 파라미터를 포함하는 트랜스포머 기반 언어 모델로, GPT [Brown et al., 2020], BloomZ [Muennighoff et al., 2022], LlaMA [Touvron et al., 2023]와 같은 방대한 데이터 세트로 훈련됩니다.
LLMs는 트랜스포머 디코더 모델을 기반으로 하며, 여러 주의(attention) 레이어를 쌓아 매우 복잡한 신경망을 만듭니다. 기존 LLM의 아키텍처와 사전 학습 목표는 작은 언어 모델과 유사하지만, 모델과 학습 데이터의 크기가 크게 증가한 점이 다릅니다. 예를 들어 T5 [Raffel et al., 2020]와 같은 일부 LLM은 트랜스포머 아키텍처의 인코더와 디코더 구성 요소를 활용하여 이해와 생성 기능을 향상시킵니다.
LLMs는 다양한 NLP 작업에서 뛰어난 성능을 발휘합니다. 텍스트 분류 [Hegselmann et al., 2023], 질문 응답 [Robinson et al., 2022], 텍스트 생성 [Muennighoff et al., 2022], 기계 번역 [Hendy et al., 2023] 등의 작업에서 탁월한 성능을 보여줍니다. 그러나 NER 작업에 적용할 때는 일부 한계가 있습니다. 이는 주로 NER이 시퀀스 라벨링 작업인 반면, LLM은 원래 텍스트 생성용으로 설계되었기 때문입니다.
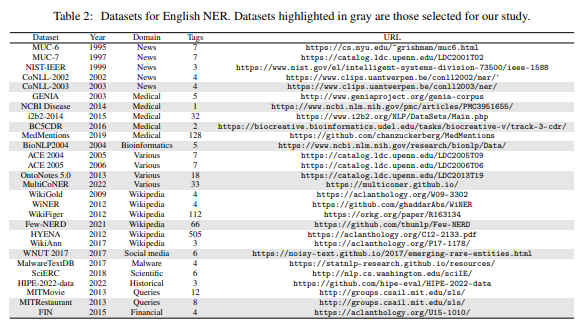
이 격차를 해소하기 위해 Wang et al. [2023]는 시퀀스 라벨링 작업을 텍스트 생성 작업으로 효과적으로 변환하는 GPT-NER 방법을 도입했습니다. GPT-NER은 NER 작업을 텍스트 생성 문제로 나타냅니다. 예를 들어, "Paris is a city" 문장에서 위치 엔티티를 식별하는 작업은 "@@Paris## is a city"와 같이 명명된 엔티티의 경계를 표시하는 특수 토큰을 사용하여 나타낼 수 있습니다. GPT-NER은 중간 또는 대규모 데이터셋에서 감독 방식과 유사한 성과를 나타내었고, 소규모 데이터셋에서 감독 방식을 능가하는 결과를 보였습니다.
Ashok과 Lipton [2023]은 NER을 위한 소수 샷 학습 알고리즘인 PromptNER를 제안했습니다. PromptNER은 주석이 달린 예제와 엔티티 유형 정의 세트를 필요로 합니다. 주어진 문장에서 PromptNER은 LLM을 프롬프트하여 엔티티 목록과 해당 엔티티 유형 정의와의 적합성을 설명하는 설명을 생성합니다. PromptNER은 특정 데이터셋에서 다른 소수 샷 및 도메인 간 방법을 능가했습니다.
Laskar et al. [2023]은 다양한 NER 작업에서 ChatGPT를 평가하여 이 영역에서 LLM의 강점과 한계를 제공했습니다. Hu et al. [2023]은 임상 엔티티 인식을 위한 제로 샷 맥락에서 ChatGPT를 조사하여 ChatGPT가 GPT-3보다 더 나은 성능을 보였지만, 감독된 BioClinicalBERT 모델보다는 덜 우수하다는 것을 발견했습니다.
Kim et al. [2023]은 GPT-2와 BERT의 결합 사용을 탐구하여 대화 시스템에서 명명된 엔티티를 명확히 하는 하이브리드 접근 방식을 제안했습니다. GPT-2는 훈련 단계에서 생성기로 작동하며, 입력 문장과 목표 엔티티가 함께 사용됩니다. 추론 동안, 입력 문장은 목표 엔티티가 정확하게 일치할 수 있는지 평가하는 데 도움을 줍니다. GPT-2 기반 접근 방식의 정확도는 BERT보다 약간 낮지만, 특정 NER 작업에서 LLM을 결합하는 가능성을 보여줍니다.
De Toni et al. [2022]는 역사적 텍스트에서 멀티태스크 T0 모델을 테스트하여, 역사적 및 다국어 맥락에서 NER의 도전에 대해 논의했습니다. Kammer et al. [2023]는 독일어 의학 텍스트의 타원형 복합 명사 구문(ECCNP)의 고유한 도전을 다루기 위해 트랜스포머 아키텍처 기반 생성 모델을 개발하여 높은 정확도를 달성했습니다.
Li et al. [2023]는 정보 추출(IE), 특히 NER 및 관계 추출(RE)에서 LLM 성능을 개선하기 위해 코드 기반 LLM(Code-LLMs)을 사용하는 새로운 접근 방식을 도입했습니다. 이 접근 방식은 IE 작업을 코드 생성 작업으로 재구성하여 구조화된 출력을 더 효율적으로 정렬합니다. 코드 스타일 프롬프트를 사용하면 코드-LLMs가 IE 및 소수 샷 학습 설정에서 NL-LLMs보다 더 나은 성능을 발휘할 수 있습니다.
LLM에 대한 최근의 열정에도 불구하고, 이러한 모델은 비용이 많이 든다는 점을 기억해야 합니다. LLM의 주요 단점은 훈련 비용이 상당하다는 점으로, 이는 현재 이 모델의 광범위한 채택을 방해하는 주요 장애물입니다. 그러나 이러한 문제를 해결하고 더 효율적이고 비용 효율적으로 만들기 위한 노력이 진행 중입니다.
4.6 그래프 기반 방법
Marcheggiani와 Titov [2017]의 연구는 NLP에서 그래프 컨볼루션 네트워크(GCN) [Kipf and Welling, 2016]를 사용하는 길을 열었습니다. GCN 기반 방법은 각 토큰을 그래프의 노드로 간주하고, 엣지는 이웃 노드와의 문맥적 링크를 나타냅니다.

GCN을 사용하여 NER 작업을 수행한 Cetoli et al. [2017]의 연구는 OntoNotes 5.0 데이터셋 [Weischedel et al., 2013]에서 성능이 크게 향상되었음을 보여줍니다. Liu et al. [2019b]는 GCN을 기반으로 그래프 임베딩을 생성하는 아키텍처를 제안하였으며, 이 그래프 임베딩은 토큰 임베딩과 결합되어 Bi-LSTM-CRF 네트워크를 통해 명명된 개체를 추출합니다. Harrando와 Troncy [2021]는 NER을 전통적으로 시퀀스 라벨링 문제로 간주했지만, 이를 각 토큰이 노드로 표현되는 그래프 분류 문제로 간주할 수 있다고 제안했습니다. 이 접근법은 유망한 결과를 보여줍니다.
5 저자원 NER
최근 신경망과 트랜스포머 기반 방법이 NER에서 좋은 성과를 보였지만, 충분한 양의 데이터가 필요합니다. 라벨이 달린 데이터를 구하기 어려운 경우 성능이 크게 저하될 수 있습니다. 이 섹션에서는 이 문제를 해결하기 위한 몇 가지 방법을 소개합니다.
5.1 전이 학습
전이 학습은 한 작업에서 얻은 지식을 관련 작업에 적용하는 기법입니다 [Zhuang et al., 2020]. NER에서 전이 학습은 일반 텍스트 데이터에서 모델을 사전 학습한 다음, 특정 NER 작업을 위해 소규모 데이터셋에서 미세 조정하는 것을 포함합니다. 예를 들어, Lee et al. [2017]는 건강 데이터의 익명화를 위해 RNN을 사용한 전이 학습을 탐구했으며, Francis et al. [2019], Liu et al. [2021b]는 트랜스포머를 사용한 NER 전이 학습의 성능 향상을 보여주었습니다. 최근 Fabregat et al. [2023]는 생물 의학 명명된 개체를 감지하기 위해 Bi-LSTM과 CRF 기반의 여러 아키텍처를 제안했습니다.
5.2 데이터 증강
데이터 증강은 기존 데이터를 사용하여 데이터셋의 양을 인위적으로 늘리는 방법입니다. 이는 작은 변경을 가하거나 [Dai and Adel, 2020; Sawai et al., 2021; Duong and Nguyen-Thi, 2021], 생성 방법을 사용하여 새 데이터를 만드는 것을 포함합니다. NER에서는 단어의 라벨을 변경할 수 있는 변형을 적용하기 어렵지만, 일부 연구자들은 이를 위해 데이터 증강 기술을 적용하려고 시도했습니다 [Dai and Adel, 2020]. GPT3Mix [Yoo et al., 2021]와 같은 기법을 통해 LLM을 활용한 데이터 증강이 가능해질 수 있습니다.
5.3 능동 학습
능동 학습은 반지도 학습의 한 형태로, 학습 알고리즘이 학습하고자 하는 데이터를 선택할 수 있으면 더 나은 성능을 발휘할 수 있다는 아이디어입니다 [Settles, 2009]. 능동 학습은 NER에서 적은 데이터로도 성능을 향상시키거나 동일한 성능을 유지하면서 필요한 데이터와 주석을 줄일 수 있습니다 [Siddhant and Lipton, 2018; Shen et al., 2017; Yan et al., 2022].
5.4 소수 샷 학습
소수 샷 학습은 적은 훈련 데이터로 정확한 기계 학습 모델을 구축하는 것을 목표로 합니다. 이를 위해 데이터 증강 또는 사전 훈련된 모델을 특징 추출기로 사용하거나, 이미 훈련된 모델을 새로운 데이터로 미세 조정하는 방법이 사용됩니다 [Wang et al., 2020]. Yang and Katiyar [2020]는 최근 이 방법을 기반으로 한 접근법을 제안했습니다.
5.5 제로 샷 학습
제로 샷 학습은 이전에 접한 적이 없는 클래스에 요소를 할당하는 사전 훈련된 모델을 사용하는 것입니다 [Larochelle et al., 2008; Lampert et al., 2013; Ding et al., 2017]. NER에서 새로운 유형의 명명된 개체를 감지하는 데 사용할 수 있습니다. Aly et al. [2021]는 텍스트 설명을 사용하는 아키텍처를 제안했습니다. Van Hoang et al. [2021]는 외부 지식을 통합하여 제로 샷 학습을 수행했습니다. 이러한 방법은 라벨이 적거나 없는 저자원 언어에 유용할 수 있습니다 [Yang et al., 2022; De Toni et al., 2022].
이러한 다양한 방법들은 NER의 성능을 개선하고, 특히 라벨이 적거나 없는 상황에서 유용할 수 있습니다.
6 소프트웨어 프레임워크
이 섹션에서는 오늘날 가장 잘 알려져 있고 널리 사용되는 NER 프레임워크를 소개합니다:
- OpenAI: GPT 모델을 포함한 다양한 AI 도구를 제공하며, 텍스트 생성, 질문 응답 등 다양한 작업을 수행할 수 있습니다. NER에 초점을 맞춘 것은 아니지만, OpenAI는 이제 이 도메인을 탐색하기 시작했습니다. API는 유연성과 사용자 친화성이 특징이며, 안전하고 윤리적인 AI 사용을 강조합니다.
- spaCy: 고급 자연어 처리를 위한 파이썬 오픈 소스 라이브러리로, 정보 추출 시스템 또는 일반 자연어 처리 시스템을 쉽게 구축할 수 있도록 설계되었습니다. 토큰화, 분류, 품사 태깅, NER 등의 분석 작업을 제공합니다. CNN 및 트랜스포머를 기반으로 한 다양한 사전 훈련된 모델을 사용하거나 특정 데이터셋에 대해 재훈련할 수 있습니다【Honnibal and Montani, 2017】.
- NLTK: 자연어 처리를 위한 파이썬 모듈 모음으로, WordNet과 같은 50개 이상의 말뭉치와 어휘 자원을 통합하고, 토큰화, 품사 태깅, 감정 분석, 주제 세분화 및 음성 인식 등의 텍스트 분석 작업을 위한 라이브러리를 제공합니다【Bird, 2006】.
- Stanford CoreNLP: 스탠포드 대학의 관련 연구 그룹이 개발한 자바로 작성된 자연어 분석 도구 세트로, 텍스트를 토큰으로 분리하고, 품사 태깅을 수행하며, CRF 기반 모델을 사용하여 NER을 위한 모델을 훈련시킵니다. 영어, 스페인어, 독일어 및 중국어에 대해 NER을 사용할 수 있습니다【Manning et al., 2014】.
- Apache OpenNLP: NER, 언어 감지, 품사 태깅, 청킹 등의 일반적인 NLP 작업을 지원하는 라이브러리입니다. OpenNLP는 각 유형의 명명된 개체에 대해 최대 엔트로피를 기반으로 한 전문화된 모델을 제공합니다【Kwartler, 2017】.
- Polyglot: Java용 NLP 파이프라인으로, 다른 프레임워크보다 훨씬 더 많은 언어를 처리할 수 있습니다. NER 모델은 40개의 다른 언어에 대해 제공됩니다【Al-Rfou et al., 2015】.
- Flair: 다국어 응용 프로그램을 지원하는 NLP 파이프라인을 생성할 수 있는 오픈 소스 라이브러리입니다. Flair 자체 임베딩뿐만 아니라 ELMo 및 BERT 임베딩도 제공합니다【Akbik et al., 2019】.
- Hugging Face: 오픈 소스 NLP 기술을 제공하며, 여러 사전 훈련된 모델에 대한 API를 제공합니다. 사용자가 딥러닝 모델을 생성, 훈련 및 공유할 수 있는 협업 플랫폼도 제공합니다【Wolf et al., 2020】.
- Gate: Java로 작성된 도구로, 여러 NLP 커뮤니티에서 다양한 언어를 위해 사용됩니다. ANNIE라는 정보 추출 시스템을 제공하며, 사람, 장소 및 조직과 같은 여러 유형의 개체를 인식할 수 있습니다【Cunningham, 2002】.
- TNER: Pytorch로 구현된 NER 모델을 훈련하고 조정하는 파이썬 라이브러리입니다. 직관적인 인터페이스를 제공하는 웹 애플리케이션이 포함되어 있어 예측을 시각화할 수 있습니다【Ushio and Camacho-Collados, 2022】.
다음과 같은 패키지를 통해 다른 언어에서도 접근할 수 있습니다:
- openNLP: Apache OpenNLP 라이브러리의 기능을 R 환경에서 인터페이스로 제공하는 R 패키지.
- spacyr: R을 spaCy와 연결하는 패키지로, spaCy의 사전 훈련된 언어 모델을 사용하여 NER을 수행할 수 있습니다.
- reticulate: R과 파이썬 간의 상호 운용성을 제공하여, Hugging Face와 같은 파이썬 라이브러리에 R 내에서 접근할 수 있게 합니다.
이러한 다양한 프레임워크는 NER 작업을 포함한 다양한 NLP 작업을 지원하며, 각 프레임워크는 특정 작업 및 언어에 대해 최적화된 기능을 제공합니다.
7 NER 시스템 평가
NER 시스템의 평가에는 주석 체계, 평가 전략 및 메트릭이 필요합니다. 각각의 요구 사항에 대해 아래에서 논의합니다.
7.1 주석 체계
엔티티를 분할하고 라벨링하기 위해 여러 유형의 주석 체계가 제안되었습니다. 이러한 주석 체계나 인코딩은 문장에서 엔티티의 유형과 위치를 결정하는 데 사용됩니다. NER 작업을 시퀀스 라벨링 작업으로 간주할 때, 주어진 텍스트 시퀀스에 대해 해당 시퀀스 태그를 찾는 것이 목적입니다. 기존의 주석 체계에서 명명된 엔티티의 첫 번째 토큰은 B(Begin)로 태그가 지정됩니다. 명명된 엔티티가 여러 토큰으로 구성된 경우, 마지막 토큰은 E(End) 또는 I(Inside)로 태그가 지정되며, 중간 토큰은 I로 태그가 지정됩니다. 명명된 엔티티의 일부가 아닌 토큰은 O(Outside)로 태그가 지정됩니다. 주석 체계는 이러한 네 가지 태그 중 일부 또는 전부를 포함할 수 있습니다. 일반적인 체계는 다음과 같습니다: BIO, IO, IOE, IOBES, IE 및 BIES.
- IO 체계: 가장 단순한 방법으로, 데이터셋의 각 토큰이 I 또는 O 태그를 받습니다. I 태그는 명명된 엔티티를 나타내고, O 태그는 다른 단어를 나타냅니다. 연속적인 동일 유형의 엔티티 이름을 구별할 수 없는 제한이 있습니다.
- BIO 체계: CoNLL 컨퍼런스에서 널리 사용되며, 각 토큰에 세 가지 태그 중 하나를 할당합니다: 명명된 엔티티의 시작(B), 엔티티 내의 태그(I), 비엔티티 단어를 나타내는 외부 태그(O).
- IOE 체계: IOB와 유사하지만, 명명된 엔티티의 시작(B) 대신 엔티티의 끝(E)을 나타냅니다.
- IOBES 체계: IOB 체계의 대안으로, 명명된 엔티티의 경계에 대한 더 많은 정보를 제공합니다. 네 가지 태그를 사용합니다: 엔티티의 시작(B), 엔티티 내의 태그(I), 엔티티의 끝(E), 단일 토큰 엔티티(S), 비엔티티 단어(O).
- IE 체계: IOE와 유사하지만, 비엔티티 단어의 끝을 E-O로, 나머지는 I-O로 라벨링합니다.
- BIES 체계: IOBES의 확장으로, 비엔티티 단어의 시작(B-O), 내부 태그(I-O), 끝(E-O), 두 엔티티 사이의 단일 비엔티티 토큰(S-O)을 사용합니다.
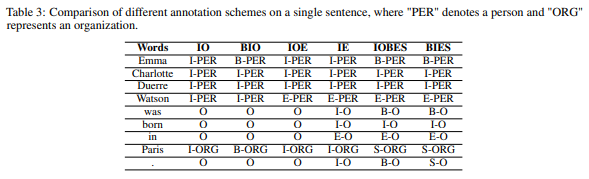
주석 체계는 NER 성능에 영향을 미칠 수 있습니다. 예를 들어, Alshammari와 Alanazi [2021]의 연구에서는 아랍어 기사에서 IO 체계가 다른 체계보다 뛰어나다고 발견했습니다. Chen et al. [2021b]의 연구에서는 IO 체계가 BIO 및 BIEO 체계보다 철강 전자 상거래 데이터에 더 적합하다고 나타났습니다.
7.2 평가 전략: 정확한 평가 또는 완화된 평가
NER 시스템의 평가는 예측을 골드 표준과 비교하는 것에 기반합니다. 이 비교에서는 정확한 평가 또는 완화된 평가 중 하나를 사용할 수 있습니다. 정확한 평가에서는 명명된 엔티티의 경계와 유형이 골드 표준과 정확히 일치해야 합니다. 반면, 완화된 평가는 올바른 유형을 가진 엔티티가 경계가 일치하지 않더라도 점수를 받는 시스템을 기반으로 합니다. MUC [Grishman and Sundheim, 1996b]와 ACE [Doddington et al., 2004] 평가는 완화된 평가 방법을 기반으로 하며, CoNLL-2003 [Sang and De Meulder, 2003]은 정확한 평가를 사용합니다.
7.3 메트릭
클래식한 메트릭인 정밀도, 재현율 및 F1 점수는 명명된 엔티티를 평가하는 데 자주 사용됩니다:
- 정밀도: 모델이 성공적으로 인식한 명명된 엔티티의 비율입니다.

- 재현율: 모델이 인식한 명명된 엔티티의 비율입니다.

- F1 점수: 정밀도와 재현율 간의 균형을 반영합니다.

위의 메트릭은 각 엔티티 클래스에 대해 계산할 수 있으며, 여러 유형의 엔티티를 고려할 때 집계할 수 있습니다:
- 매크로 평균: 각 클래스에 대해 메트릭(F1 점수 등)을 별도로 계산한 다음, 이 값을 평균한 것입니다.
- 마이크로 평균: 각 샘플에 동일한 가중치를 부여합니다.
또한, Fu et al. [2020]의 연구에서는 엔티티의 길이, 밀도 등의 속성을 정의하여 모델의 성능을 평가하는 새로운 방법을 제안했습니다. 그들은 모델이 특정 속성과 더 높은 상관관계를 가질 수 있음을 발견했습니다.
8 NER 데이터셋
명명된 엔티티는 종종 인물, 장소, 조직과 같은 광범위한 범주에 속하지만, 더 좁은 범주로도 나뉠 수 있습니다. 예를 들어, 책, 정기간행물, 잡지 등으로 분류될 수 있습니다. 다음은 다양한 도메인(의료 데이터, 뉴스, 소셜 미디어 등)에서 1에서 505 종류의 엔티티를 포함하는 26개의 영어 NER 데이터셋에 대한 개요입니다.
주요 NER 데이터셋
- CoNLL-2003: Reuters의 뉴스 기사로 구성된 데이터셋.
- OntoNotes 5.0: 전화 통화, 뉴스와이어, 뉴스그룹, 방송 뉴스, 방송 대화, 블로그, 종교 텍스트 등 다양한 장르의 텍스트로 구성된 데이터셋.
- WNUT2017: 트윗, Reddit 댓글, YouTube 댓글, StackExchange와 같은 다양한 장르의 텍스트로 구성된 데이터셋.
- BioNLP2004: 2000개의 MEDLINE 초록을 제공하는 의료 데이터셋.
- FIN: 미국 증권거래위원회를 통해 공개된 금융 데이터로 구성된 데이터셋. [Alvarado et al., 2015]에 의해 주석 처리됨.
- NCBI Disease: NCBI Disease Corpus에서 질병 이름과 개념 주석을 포함하는 데이터셋.
- BC5CDR: 화학물질, 질병 및 그 관계에 대한 세 가지 별도의 기사 세트로 구성된 데이터셋.
- MITRestaurant: 온라인 레스토랑 리뷰 세트로 구성된 데이터셋.
- Few-NERD: Wikipedia 기사와 뉴스 보고서 세트로 구성된 데이터셋. 데이터가 매우 크기 때문에, 20%의 데이터(32,941 샘플)만을 사용하여 모델을 훈련시킴.
- MultiCoNER: 위키 문장, 질문, 검색 쿼리의 세 가지 도메인을 다루는 대규모 다국어 데이터셋.
다음은 비교 연구에서 사용된 데이터셋의 특성을 나타낸 표입니다:
데이터셋 이름설명샘플 수 (#)
| CoNLL-2003 | 뉴스 기사 | 22,137 |
| OntoNotes 5.0 | 다양한 장르의 텍스트 | 59,924 |
| WNUT2017 | 소셜 미디어 텍스트 | 6,161 |
| BioNLP2004 | MEDLINE 초록 | 2,000 |
| FIN | 금융 데이터 | 10,000 |
| NCBI Disease | 질병 이름 및 주석 | 6,881 |
| BC5CDR | 화학물질 및 질병 관계 | 1,500 |
| MITRestaurant | 레스토랑 리뷰 | 6,000 |
| Few-NERD | Wikipedia 및 뉴스 | 32,941 |
| MultiCoNER | 다국어 데이터셋 | 112,000 |
이러한 데이터셋들은 다양한 도메인과 언어에서 NER 시스템을 개발하고 평가하는 데 유용합니다. 각 데이터셋은 특정 도메인 또는 사용 사례에 맞게 설계되었으며, 이를 통해 NER 모델의 성능을 평가하고 비교할 수 있습니다.
참고 문헌
- CoNLL-2003: Tjong Kim Sang, E.F., & De Meulder, F. (2003). Introduction to the CoNLL-2003 shared task: Language-independent named entity recognition.
- OntoNotes 5.0: Weischedel, R., et al. (2013). OntoNotes Release 5.0.
- WNUT2017: Derczynski, L., et al. (2017). Results of the WNUT2017 Shared Task on Novel and Emerging Entity Recognition.
- BioNLP2004: Kim, J.D., et al. (2004). Introduction to the Bio-Entity Recognition Task at JNLPBA.
- FIN: Alvarado, N., et al. (2015). Leveraging Financial Text for Entity Recognition.
- NCBI Disease: Dogan, R.I., Leaman, R., & Lu, Z. (2014). NCBI Disease Corpus: A resource for disease name recognition and concept normalization.
- BC5CDR: Li, J., et al. (2016). BioCreative V CDR task corpus: a resource for chemical disease relation extraction.
- MITRestaurant: Liu, F., et al. (2013). A Fast and Accurate Entity Recognition System for Biomedical Literature.
- Few-NERD: Ding, J., et al. (2021). Few-NERD: A Few-shot Learning Benchmark for Named Entity Recognition.
- MultiCoNER: Malmasi, S., et al. (2021). MultiCoNER: A Large Multilingual Dataset for Named Entity Recognition.

9 실험
이 섹션에서는 선택된 알고리즘의 효과를 평가하기 위해 채택한 프로토콜을 자세히 설명합니다.
9.1 실험 조건
실험에 사용된 조건을 설명합니다.
9.1.1 데이터셋
실험은 다양한 도메인의 텍스트로 구성된 10개의 데이터셋에서 수행되었습니다. 데이터셋의 크기와 클래스 수가 다르기 때문에 다양한 상황에서 모델을 테스트할 수 있습니다.
9.1.2 모델
모델의 가용성(무료 및 오픈 소스)과 사용자 지정 데이터셋에서 모델을 훈련할 수 있는 능력에 따라 프레임워크를 선택했습니다. 따라서 Flair, Stanford CoreNLP, Apache OpenNLP, spaCy 및 Hugging Face가 선택되었습니다. NLTK는 Stanford Named Entities 태거를 포함하고 있기 때문에 분석에서 제외되었습니다. 프레임워크가 여러 알고리즘을 포함하는 경우 여러 모델을 선택했습니다. spaCy의 경우 소형 CNN(en_core_web_sm), 대형 CNN(en_core_web_lg), 기본 RoBERTa 기반 트랜스포머의 세 가지 모델을 선택했습니다. Hugging Face의 경우 기본 BERT 아키텍처, 대문자와 소문자 구분 버전, BERT의 증류된 버전, 넓은 RoBERTa 아키텍처의 네 가지 모델을 선택했습니다. OpenAI의 경우, 가장 최근 업데이트된 GPT 버전인 GPT-4-1106-preview를 선택했습니다.
9.1.3 하드웨어 조건
모든 실험은 Amazon Linux 2와 Python 3.10이 설치된 Amazon p3.2xlarge VM에서 수행되었습니다. 인스턴스에는 8 vCPU, 16 GB의 GPU(Nvidia Tesla v100) 및 64 GB의 메모리가 있습니다.
9.2 방법
실험은 다음 세 단계로 구성되었습니다:
9.2.1 데이터 형식 및 주석 체계
각 코퍼스는 BIO 체계에 따라 CoNLL-U 형식으로 인코딩되었습니다. 각 프레임워크는 데이터 표현을 위해 고유한 형식을 사용하므로, 초기 CoNLL-U 형식은 해당 프레임워크 전용 형식으로 변환해야 했습니다. GPT-4의 경우, 각 데이터셋에 맞게 특정한 프롬프트를 사용했습니다. 각 프롬프트는 대상 명명된 엔티티의 주요 범주를 설명하고 몇 가지 예제를 포함합니다.
9.2.2 모델 및 하이퍼 파라미터
- Flair: 표준 LSTM-CRF 네트워크를 사용했습니다. 하이퍼 파라미터는 grid search를 통해 얻었으며, hidden_layer_size는 (64, 128, 256)에서, learning_rate는 (0.05, 0.1, 0.15, 0.2)에서 선택했습니다.
- Hugging Face: CRF를 사용하여 엔티티를 디코딩했습니다. learning_rate는 (0.001, 0.0001, 0.00001)에서 선택했고, 에포크 수는 10, weight_decay는 0.01로 설정했습니다.
- Apache OpenNLP: 기본 하이퍼 파라미터 값을 사용했으며, 반복 횟수만 변경 가능했기 때문에 기본값인 300을 유지했습니다.
- Stanford CoreNLP 및 spaCy: 사전 훈련된 모델의 값을 사용했습니다.
9.2.3 평가
결과의 품질을 평가하기 위해 정확한 평가 전략을 사용했습니다. 선택한 메트릭은 F1 점수로, 이는 정밀도와 재현율을 반영합니다. Apache OpenNLP의 경우, 일부 데이터셋은 이 프레임워크가 세 가지 유형의 명명된 엔티티(인물, 조직, 위치)만 감지하기 때문에 제외되었습니다.
9.3 결과 및 논의
실험 결과는 다음과 같습니다.

- 대규모 훈련 세트가 있는 데이터셋(OntoNotes, CoNLL-2003, Few-NERD, MultiCoNER)의 경우 트랜스포머 기반 아키텍처가 최고의 결과를 제공합니다.
- BioNLP2004의 경우, LSTM-CRF와 CRF가 Hugging Face의 트랜스포머보다 약간 더 나은 결과를 보였습니다. 이는 생물 의학 데이터가 트랜스포머의 사전 훈련 데이터와 크게 다르기 때문일 수 있습니다.
- FIN과 같은 소규모 훈련 세트가 있는 데이터셋에서는 LSTM-CRF가 트랜스포머보다 훨씬 더 나은 결과를 보였습니다.
- MITRestaurant 및 WNUT2017과 같은 소규모 데이터셋에서는 xlm-roberta-large가 가장 좋은 성능을 보였습니다.
Friedman 테스트 결과, 중간 값 간의 통계적 차이가 있음을 나타냈습니다.
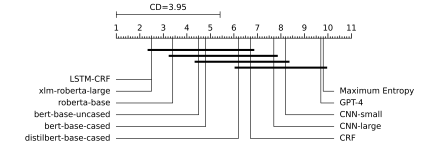
Nemenyi의 사후 테스트 결과는 LSTM-CRF와 모든 트랜스포머 간에 유의미한 차이가 없음을 보여주었습니다.
이러한 결과는 트랜스포머가 큰 데이터셋에서 잘 작동하지만, 소규모 데이터셋에서는 전통적인 LSTM-CRF가 더 나은 성능을 보일 수 있음을 시사합니다. 각 모델의 평균 순위를 나타내는 CD 다이어그램은 모델 간의 성능 차이를 시각적으로 보여줍니다.
10 결론 및 전망
이 논문은 분류 맥락에서 명명된 엔티티 인식(NER)에 대한 최근 발전에 대한 포괄적인 조사 보고서입니다. 특히, LLMs, 그래프 기반 접근법 및 소규모 데이터셋에서 모델을 훈련하는 방법과 같은 최신 방법들을 검토했습니다. 다양한 특성을 가진 데이터셋에서 가장 인기 있는 프레임워크와 도구를 평가했습니다.
트랜스포머 기반 아키텍처는 특히 큰 데이터셋에서 높은 성능을 발휘했습니다. 이는 이들이 갖는 방대한 파라미터와 적응성 덕분입니다. 그러나 GPT 및 GPT-4와 같은 특정 모델은 NER 작업에서 일관되게 상위에 랭크되지 않았습니다. 이는 복합 명명된 엔티티를 구별하고 정확하게 감지하는 데 어려움을 겪기 때문입니다. 반면, LSTM-CRF 모델은 다양한 데이터셋에서 일관되고 견고한 성능을 보여주어 다양한 응용 분야에서 신뢰할 수 있는 선택지로 자리잡고 있습니다. 생물 의학 데이터셋의 특정 요구 사항은 도메인 별 모델링의 중요성과 트랜스포머 모델에서 일반적으로 사용되는 사전 학습의 한계를 강조합니다.
미래를 바라보며, LLMs 모델이 NER을 향상시키는 역할은 과소평가될 수 없습니다. 현재 GPT와 같은 모델이 특정 NER 작업에서 한계를 보이고 있지만, 언어 모델의 급속한 발전은 더 정교하고 정확한 엔티티 인식 시스템으로 이러한 기술을 통합할 수 있는 유망한 길을 제시합니다. GPT-4의 세밀한 텍스트 이해 및 생성 능력은 지속적인 학습 및 적응과 결합하여 복합 및 도메인 별 엔티티와 관련된 현재의 문제를 극복할 수 있는 기회를 제공합니다.
향후 연구는 NER 성능을 개선하기 위해 GPT-4 및 유사한 모델의 능력을 활용하고 적응시키는 것을 목표로 해야 합니다. 여기에는 이러한 모델을 특정 NER 작업에 맞추어 미세 조정하는 것뿐만 아니라, 혁신적인 훈련 기법, 데이터 증강 전략 및 모델 아키텍처를 탐구하여 LLMs의 문맥 이해와 유연성을 활용하는 것이 포함됩니다. 또한, 다양한 시나리오에서 성능을 최적화하기 위해 전처리 기법과 그 영향을 깊이 탐구하는 것이 필요합니다.
참고 문헌
- Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., ... & Amodei, D. (2020). Language models are few-shot learners. arXiv preprint arXiv:2005.14165.
- Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., ... & Stoyanov, V. (2019). RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv preprint arXiv:1907.11692.
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30.
- Wang, A., et al. (2023). GPT-NER: Named Entity Recognition via GPT-based text generation.