
김광호 대표님 - 음성처리 (3)
메일 주소 : kwangho.kim@voiceprint.kr
(강의 들은 학생임을 밝히기)
음성인식 - 시계열 data
[voice 연구]
- 화자인식
- 음성인식
- 음성합성 (네오피엔스)
+ 노래 (보컬) (magenta, ...)
[sound 연구]
- 음악(악기소리)
- 그 외 사운드 (ex. 지하철 소리, 강아지 짖는 소리..)
[음성처리 분야의 목표]
- 화자 인식 (발화자가 누구인가?)
- 음성 오디오 신호가 들어오면, 잡음처리(노이즈 제거) / 음성특징 추출(시계열 데이터 - 벡터의 시퀀스를 만듦).
y = A * sin(2*pi*f*t + phi)

A : Amplitude (진폭 크기)
f : 주파수 (진동수) -> 천천히 가면 저주파, 빨리 가면 고주파
phi : 위상 (phase) -> 형태를 바꾸진 않고, 좌우로 옮긴다.
일상에서 들리는 소리들은 다 더해져있다. 즉, 한꺼번에 들린다.
사람이 들을 수 있는 주파수의 범위는 제한적. (20헤르츠 ~ 2만헤르츠)
이 범위를 벗어나는 소리를 "초음파"라고 한다.
기계는 2진법만 이해할 수 있다.
16bit : 0000000000000000 ~ 1111111111111111 ( = 2^16 = 65,535)
bit는 해상도를 나타낸다. (칸을 굉장히 많이 쪼개니까)
- 음색
피아노의 소리는 특정 주파수를 만들어내는 것과 같음 (전자피아노)
아날로그 vs 디지털
디지털은 아날로그 신호를 절대 뛰어넘을 수 없지만,
일반인이 귀로 들을 수 있는 범위 내에서는 아날로그와 구별할 수 없을 정도의 수준까지 따라가고 있다.
디지털은 여러번 복사/전달 되어도 형태가 변하기 않기 때무에, 소비자에게는 최고!
아날로그 신호를 디지털 신호로 변환
아날로그-----> 디지털 : 마이크
디지털 --> 아날로그 영상 필름.
sampling 단계
시간 간격에 따라서 가장 가까운 값으로 추출. -----> 오차 빌생 (양자화 quantization; 연속적으로 보이는 양을 자연수로 셀 수 있는 양으로 재해석하는 것. 즉, 근사치로 설정.)
ex) [3,4,3,-2,-3,...] 라고 표시 되었다면, 숫자 하나당 8bit로 저장. [00000011,00000100 ....]
시간 간격을 좁혀서 값이 크면, 음질이 좋아진다. 단점은 정보의 양이 많아진다.
Sampling Rate이 높은 장비는 고음 표현이 잘 된다. 즉, 음색 표현을 잘 하기 위해선 sampling rate이 높아야 한다.
8,000 Hz 전화
44,100 Hz 오디오 CD, MPEG-1 오디오(VCD, SVCD, MP3)
48,000 Hz 테입 레코더
88,200 Hz CD를 위해 사용할 때에 몇몇 전문 녹음 장비
96,000 Hz DVD-Audio,
192,000 Hz DVD 오디오,
2,822,400 Hz : SACD
을 비교했을 때, 고음의 해상도 차이가 구별 가능하다.
1만6천 헤르츠 : 음성 인식에서 많이 사용.
ex) 휴대폰 - 무선통신 (아날로그 신호에 2진화된 정보를 심는다. )
42, 48 헤르츠 : 음악 / 방송에서 많이 사용.
"나이퀴스트 이론"
: 신호는 그 신호에 포함된 가장 높은 진동수의 2배에 해당하는 빈도로 일정한 간격으로 샘플링하면 원래의 신호로 복원할 수 있다는 샘플링 이론
ex) 8k의 아날로그 신호에 저장된 정보를 전달하기 위해서는 디지털 신호는 적어도 16k로 설정해야 한다.

신호의 모양을 얻으려면 신호의 최고 주파수보다
적어도 10배 높은 샘플링 속도가 필요.
신호의 최고점과 최저점을 알 수 있도록 하는 것이 좋은데, 이는 실젤로
우리 공기중에는 소리가 2만헤르츠까지만 있지 않다. 귀에는 안들리지만, 공기중에 진동하고 있는 소리가 있다
공기 중에는 인간이 들을 수 있는 소리 외에 다른 소리가 있다.
디지털화 하기 위해 녹음을 하면 공기중에 있는 초음파 소리들이 입력 된다.
2만 헤르츠보다 높은(더 빠른) 주파수가 들어오게 되면, 오동작하는 위치의 점을 찍게 된다
공기중에 있는 주파수보다 너 낮은 점이 찍힌다. (오류를 범하게 됨) ghost freuquency = aliasing frequency
이는 사람이 가청 범위라서, 들리게 된다.
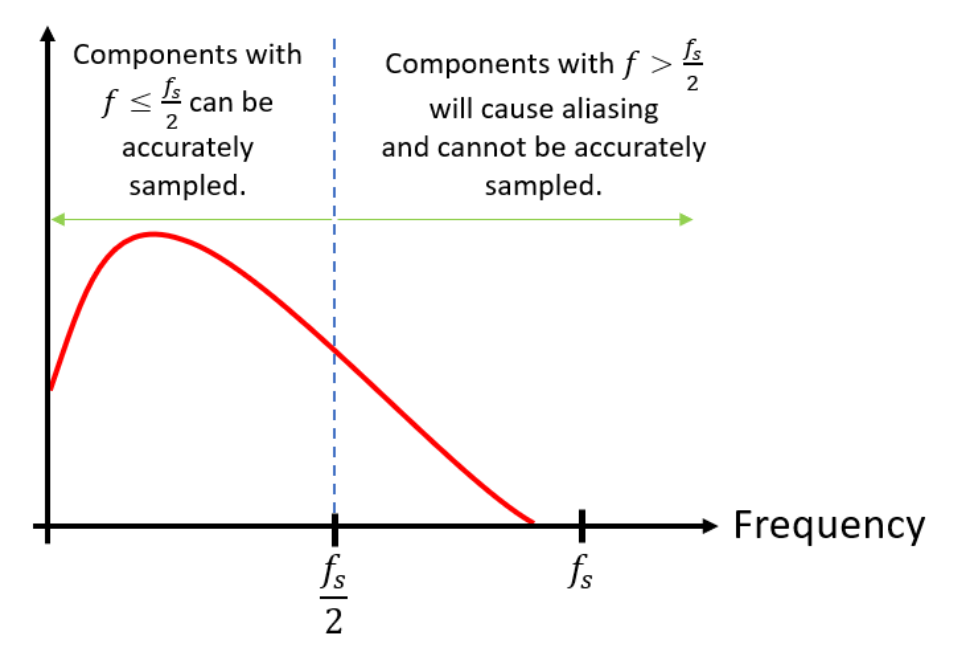
이를 위해 anti-aliasing filter 등장
: 사람이 들을 수 없는 범위의 주파수는 잘라내자!
2만 헤르츠를 걸면, 무 자르듯이 딱 자를 수는 없기에
최대한 가파르게 자르도록 한다.
22,050 Hz x 2배
결론
숫자의 시퀀스가 도출된다.
WAV 또는 WAVE는 웨이브폼 오디오 포맷(웨이브 오디오 포맷, Waveform audio format)의 준말로 개인용 컴퓨터에서 오디오를 재생하는 마이크로소프트와 IBM 오디오 파일 포맷 표준이다.

ADPCM은 아날로그 신호를 디지털로 변환하기 위한 PCM방식의 일종으로 PCM방식에 비해 적은 데이터를 사용하여 값을 표시할 수 있는 장점이 있습니다. 다음 그림과 같이 PCM의 데이터를 표시하기 위해서는 8비트 또는 16비트의 데이터가 필요하지만 ADPCM방식은 이전 샘플값과의 차이를 나타내기 때문에 4비트만으로 동일한 값을 표시할 수 있습니다
모든 압축에는 손실 압축(mp3) / 무손실 압출(flac)
손실 압축 : 데이터를 압축했다가 다시 풀면, 원본이랑 다르다.
오디오 = 아날로그에 있는 주파수가 다른 여러가지 신호들의 결합
결합을 분해하는 과정
Fourier Transform
articles about speech recognition
ratsgo.github.io
Discrete Fourier Transform
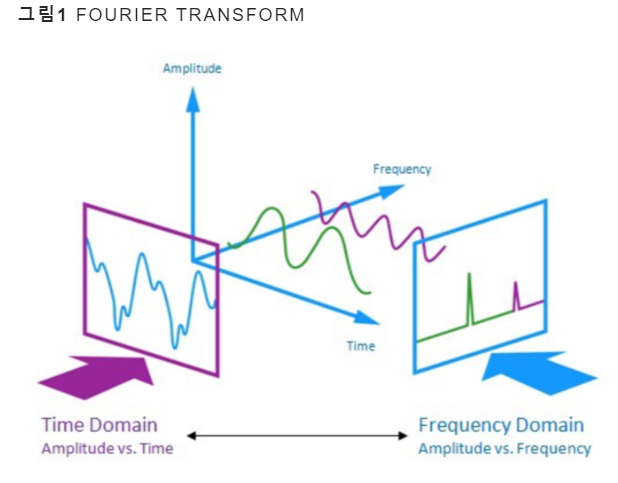
short-time fourier transform
보는 관점에 따라서 다르게 보인다.
사인파 - window (20ms 간격으로 소리가 끝날때까지 slide) ; 가로축은 시간에 따른 t
window 1개당 320(= 16,000 * 20 / 1000)개의 sample 존재.
sampling 주파수 = 16,000 Hz (1초 = 1000ms)
*window를 사용하는 이유
- 시간에 대한 정보를 나타내기 위해서.
- 정보가 급격하게 변하는 것을 방지하기 위해 겹쳐지는 부분을 만들어서 점차적으로 변화하하도록 함.
- 계산 시간 단축 (시간이 오래 걸리는 모델은 반드시 성능이 낮아진다)
사인파의 값을 분해하여,

시간에 따른 벡터의 시퀀스 생성
벡터의 시퀀스에서 가로축은 frame에 따른 t.
벡터 공간에서 시간의 순서에 따라 점이 찍히는데, 그 점이 흘러가는 모양을 보고 ㄱ, ㄴ, .. 구분.
각 time t 마다 energy(정보량)에 차이가 있다.
벡터의 시퀀의 내의 하난의 벡터의 값은 복소수 형태. a + bj (by. 오일러 공식) -> energy를 찾는 개념
이때, 복소수도평면을 그려보면, 아래 그림과 같다.

이때, 복소수의 값은 크기와 방향이 있는 벡터의 형태.
여기서 방향은 고려하지 않고, 크기만을 기록하여 spectrogram을 만든다.
spectrogram

마이크만 가져다 대도 잡음이 잡힘.
사람마다 고유 진동수가 다르다. (fundamental frequency)
사람 하나의 음색이 아니라, 여러 주파수들의 결합으로 음색이 만들어짐.
에너지가 높은 쪽이 저주파대역.
매 시점마다의 벡터.
시간에 따른 정보량이 다른 것들과 다르기 때문에 발음을 구별할 수 있다.
아 와 야 는 벡터 값이 비슷하게 나온다. 이런 현상들 때문에, 최소 0.2초 정도는 이야기 해야 한다.
20ms = 0.02초 단위로 잘라서 미세하게 분석진행. 따라서 다양한 정보를 담고 있음 (그만큼 어려움)
자연어처리와 크게 다르지 않게, 결국은 벡터를 만들어서 벡터의 시퀀스를 생성한다.
(자연어처리에선 I 를 embedding vector로 바꾸는 것과 동일.
만약 I라는 단어를 0.2초 동안 말했다면, 벡터가 최소 10개 생기는 것. 0.02 단위로 자르기 때문에.)
단어의 시퀀스가 나오도록 자동으로 학습 시키는 과정을 수행하는 것.
ㅏ 라고 하는 것을 다양한 형태(길이, 억양, 사투리 등)로 학습을 시키면 찾아낼 수도 있다.
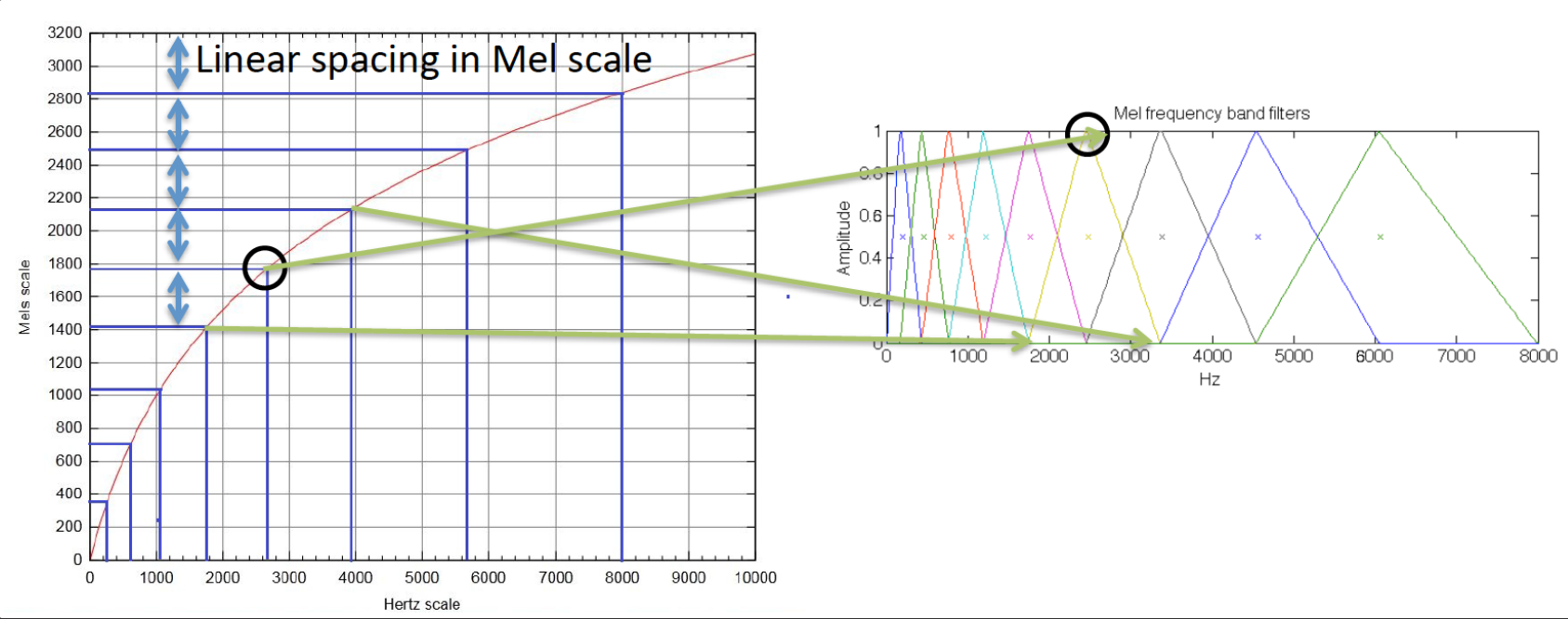
Mel-Scale Spectogram

등간격을 포기하고, 저주파 대역은 간격을 촘촘히 하고, 고주파 대역은 간격을 넓게 본다. (Mel-Frequency)

악기 경우에는, 저주파 대역에도 정보가 많을 수 있기 때문에 Raw Spectogram 사용.

n_fft :
win : 윈도우 길이
hop :
power : 벡터의 길이의 제곱을 사용하겠다는의미. => a^2 + b^2 를 사용.
Mel Filter Bank

Mel-filter의 기본 아이디어는 사람의 청력은 1000Hz 이상의 frequency에 대해서는 덜 민감하므로 1000Hz까지는 Linear하게 그 이상은 Log scale로 변환해주자! 이다.
음성 합성
[예시]
"오늘은 7월 8일 입니다"
-> 언어처리
: :오늘은 칠월십팔일 입니다
-> 스펙토그램 생성
-> 보코더 를 사용하여 wave로 만듦.
-> 음성 파일 생성.
보코더의 역할
스펙트로그램은 f에 대한정보만 담고 있음 -> neosaphience
A(크기)와 위상의 정보를 같이 나타낼 수 있어야 함.
따라서, 위상을 찾아주는 역할을 함.
(위상이 이상하면, 사람이 말하는 것처럼 들리지 않는 경우가 있음)
Tacotron

waveNet MoL -> vocoder
트럼프가 한국어를 말할 수 있는 이유
MULTI TACOTRON
음성 2개를 한 번에 학습 시킨다.
한국말 모델, 크럼프 음성 모델.
다만, 국적에 따라서 억양에 대한 차이가 생길 수는 있다.
speaker 1 번과 speaker 2번을 알려주는 방법 : speaker embedding vector를 만든다.
사람마다 벡터를 만들 수 있다는 이야기는, 사람을 구분할 수 있다는 의미. -> 화자 구분을 할 수 있다.
pyannote
speaker diarization : turn을 구분.
화자 인식이 내부적으로 포함되어 있음
음성 합성
coqui-TTS :
bark : 텍스트를 넣으면 스피치를 만드는 모델. 말에 억양을 싣는다.
[잡담]
nano gpt
gpt를 조금 쉽게 심플하게 만든 버전.
open source language model
Llama : 메타에서 나옴. 누구든지 사용 가능.