연구 주제 관련 논문을 서치하다가 알게된 고전적인 방법이다.
이 논문은 2016년에 JMNL 저널에 나온 논문이지만, 아이디어 자체는 간단하여 지금까지도 인용이 많이 되고 있다.
알아두면 좋을 것 같아서 정리하기로 했다.
기존의 Domain Adaptation(DA) 방법에 GAN의 concept을 일부 도입한 방법이라고 이해하면 될 것 같다.
Traditional 한 DA 방법은, 주로 fixed feature representation을 추출하여 원하는 target distribution에 mapping하는 것이다.
하지만 위 논문은 representation 자체를 바꾸는 방법으로, 한 번의 training을 통해 위 결과를 도출해 낸다는 것이 가장 큰 특징이라고 할 수 있다.
Domain Adaptation이 뭘까?
가장 간단하게 설명해 보자면, 모델이 학습한 데이터의 분포와 실제로 사용할 때 input으로 받게 되는 데이터의 분포가 너무 달라서 생기는 문제를 해결하기 위해, 두 도메인 간의 분포를 줄이는 방법론이다.
아래 예시에서 왼쪽(MNIST)은 이미지에서 가장 많이 쓰이는 손글씨 데이터이고, 오른쪽(SVHN)은 실제로 일상 생활에서 사용하게 되는 데이터이다. 딱 봐도, 오른쪽 이미지가 훨씬 다양해보인다.
Image classification task에서 왼쪽 이미지로 학습시킨 모델이 오른쪽 이미지에 대해서는 classification 성능이 좋지 않다면, 그 이유는 바로 domain divergence에 있다.

따라서, 두 도메인 간의 분포 격차를 줄이기 위해서 아래와 같은 방법을 제시했다.
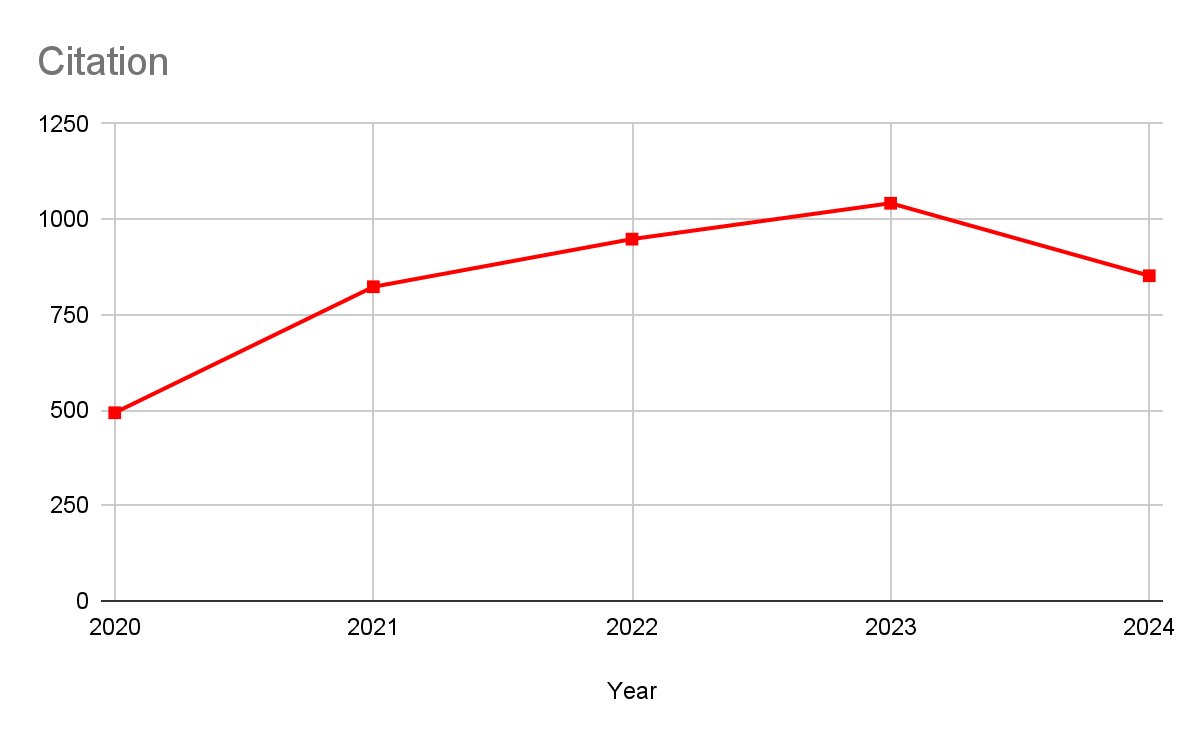
먼저, 데이터 샘플이 어떤 도메인에서 왔는지 예측하는 classifier를 만든다. ( source 도메인 / target 도메인 )
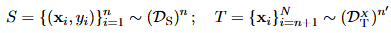
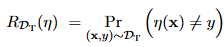
- x : input
- y : ground-truth label
- N : total data samples
- n : total source data samples
- R_Dt : Target rosk
- eta : classifier X -> Y (0,1)
source domain에서 학습된 모델이 target domain에서도 잘 작동하는 것이 핵심.
즉, Target risk를 적게 하면서 target domain에서의 error를 최소화 하는 것이 중요하다.
Target domain error는 source domain error + domain divergence로 upper bound를 정할 수 있다.
Domain Divergence
두 도메인 간의 분포를 좁히기 위해서는 먼저 두 도메인 간의 거리를 측정해야 한다.
여기서, domain divergence라는 개념이 등장하는데, 이는 두 도메인간의 거리를 측정하는 measure이다.
여기서는 Ben-David의 논문에서 H-divergence를 사용한다. (매우 유명하신 분이라고 한다.)
H-divergence란 두 도메인을 잘 구분하는 classifier를 얼마나 담을 수 있는지를 뜻하기에 도메인을 구분하는 능력을 칭한다. 실제로 거리의 개념은 아님!

- sup : upper bound를 나타내는 수식
- hypothesis class H : Binary classifier "eta"들의 집합
즉, source domain을 1로 판단할 확률 - target domain을 1로 판단할 확률로 정의한다.
( 예로, source domain을 1로 판단할 확률이 1이고, target domain도 1로 판단할 확률이 1이라면 두 값의 차는 0이 된다.
즉, classifier가 도메인을 구분하지 못한다면 위 식은 1/2 - 1/2 = 0 이 되고, 도메인을 잘 구분한다면 1-0=1 or 0-1 = -1 로 절댓값과 2배를 취하면 2가 된다.)
이때, H 안에 있는 모든 classifier들에 대해서만 계산을 진행하는데,
이런 의문이 들 수도 있다. (사실 나는 안 들었지만...;;)
Q. H의 범위를 무한히 늘리면 잘 구분하는 classifier를 H안에 충분히 넣을 수 있지 않을까?
=> The upper bound of the true minimum risk = empirical risk(what we can calculate) + model complexity
H의 범위를 무한히 늘리면 emperical risk (계산 가능) 는 0으로 수렴할 수 있을지언정, model complexity는 증가하여 결국 upper bound가 올라가게 된다.
따라서, 우리는 충분한 성능을 갖는 classifier를 갖되, 모델의 복잡도가 너무 높지 않은 최적의 값을 찾아야 한다.
Approximation
H-Divergence
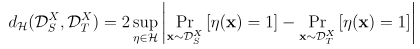
H-Divergence 에서 H가 symmetric하다면, 아래 식과 같다.
Empirical H-divergence
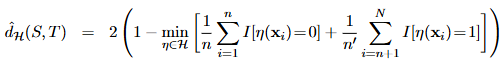
위 식은 정확한 계산이 어렵기 때문에, 아래 식으로 근사시킨다.
Proxy A Distance (PAD)

위 식에서 min( ) 부분이 아래 식에서 입실론으로 치환되어 있는 꼴이다.
즉, sample의 출처가 source domain인지 target domain인지 classifier가 정확히 구분할 수 있으면 ϵ=0 이다.
즉, 도메인이 달라지더라도 일반화 할 수 있는 모델을 만들기 위해서는,
모델 학습 단계에서 label classifier의 성능은 좋게, domain classifier의 성능은 나빠지도록 해야한다.
Domain-Adversarial neural networks(DANN) 구조
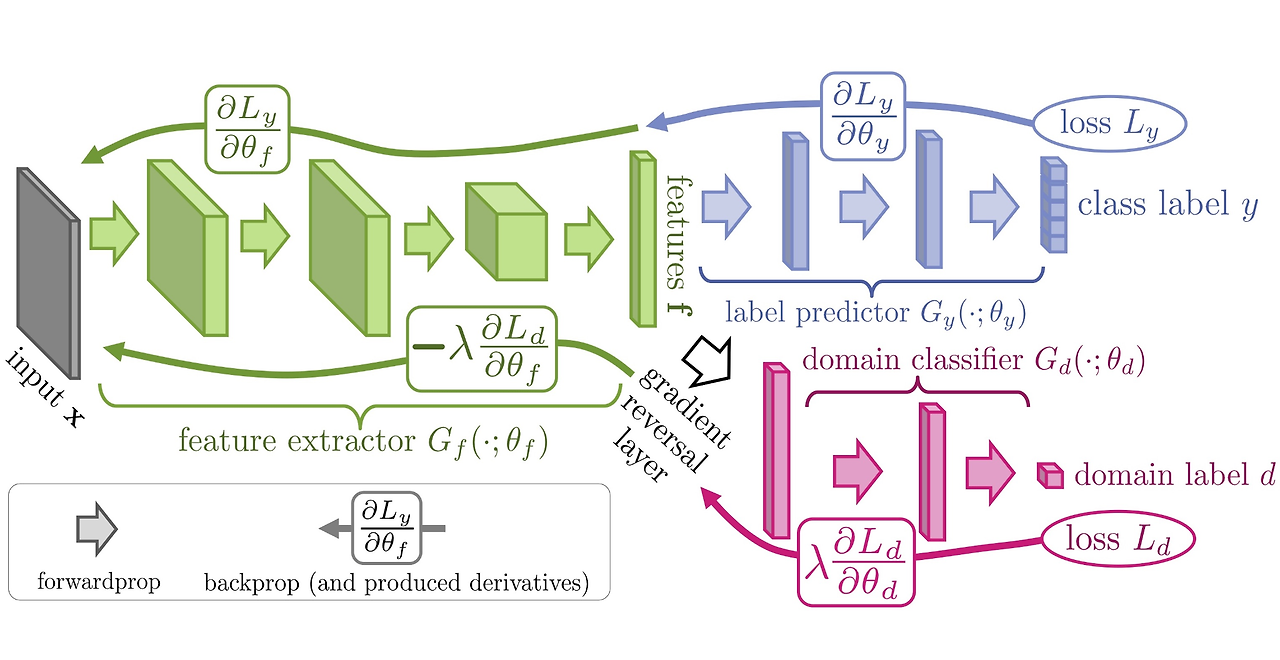
- feature extractor(Green)
- label predictor(Blue)
- domain classifier(Red)
논문의 목표는 앞의 feature extractor Gf 가 최대한 source와 target에 동시에 포함되는, domain의 특성을 지우고 class 분류에만 쓰인 특징을 뽑게 하는 것이다.
Gradient Reversal Layer
그러기 위해서, GRL을 추가하여 역전파 당시 -lamda 값을 곱하여 부호를 바꿔 전달한다.
이는 domain classifier가 헷갈리도록 하기 위함이다.
이를 통해, 1. 학습 당시의 classificaion error를 줄이고
2. Train/Test domain classification error를 최대화 할 수 있다.
Experiments
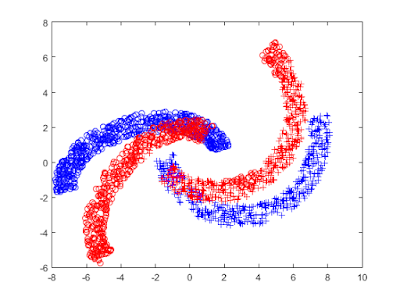
Two - moon dataset 을 사용하여, classification 문제를 해결해 보았다.
- o : Upper half-moon
- + : Down half-moon
- Blue : Source domain
- Red : Target domain
(Made by rotating the Blue one.)
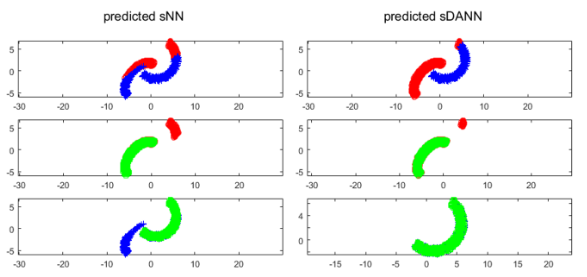
- Red : o predict / Blue : + predict
- Green : Ground truth
- sNN : shallow Neural Network
- sDANN : shallow Domain Adversal Training Neural Network
1행에서, 왼쪽 반원은 o로 예측하고 오른쪽 반원은 +로 예측해야 한다.
2행과 3행에서는, 초록색 부분이 ground-truth 이므로 초록색이 많이 보일 수록 예측을 정확하게 한 것이다.
따라서, sDANN의 성능이 더 좋다고 할 수 있다.
References
1.https://arxiv.org/pdf/1505.07818
2. https://jayeon8282.tistory.com/7
[논문 리뷰] Domain Adversarial Training of Neural Networks
이번 방학에는 domain adaptation 논문들을 정리하여 리뷰해 보려고 한다. 심심할 때 리눅스 쉘에서 자주 쓴 명령어도 정리해 기록해 보고자 한다. 지금 2020년도 기준으로 이번에 리뷰하는 [Domain Advers
jayeon8282.tistory.com
[논문 공부] DANN : Domain-Adversarial Training of Neural Networks
(paper) https://arxiv.org/abs/1505.07818 2016년 JMLR(Journal of Machine Learning Research)발표 논문. 이 논문은 Train과 test의 data distribution이 다른 경우, Domain
velog.io
'AI > Vision' 카테고리의 다른 글
| [Paper Review] CLIP :Learning Transferable Visual Models From Natural Language Supervision (0) | 2024.08.02 |
|---|
