발단
(기존 방법의 한계)
- Wav2vec2.0이나 기계학습 방법은,
비지도 학습이 오디오 인코더의 품질을 크게 향상시켰음에도 불구하고, 동등하게 높은 품질의 사전 학습된 디코더가 부족하고, 데이터셋 특유의 fine-tuning 프로토콜이 필요하다는 점이 그들의 유용성과 견고성을 제한하는 중요한 약점임을 시사한다.
기본적으로 음성 인식 시스템의 목표는 배포할 때마다 디코더에 대한 지도 학습의 미세 조정 없이도 다양한 환경에서 신뢰성 있게 작동하는 것!
따라서, 파인튜닝 필요 없는 모델을 만들겠다!!
2. 접근 방법
2.1. 데이터 처리
오디오 및 텍스트의 전처리를 거의 하지 않음! 대신 데이터셋의 크기가 매우매우 크다!
- seq2seq 모델이 standardization 을 거치지 않은 raw text 와 audio 의 expressiveness 를 충분히 학습하여 utterance 자체와 transcribe form 간의 관계를 이해하게 하기 위해서!
- ITN (inverse text normalization) 을 거치지 않아서 speech recognition pipeline 을 단순화 시키기 위해서!
인터넷에서 전사본과 짝을 이루는 오디오 데이터를 수집하여 데이터셋을 구성.
이때, 대부분의 전사본은 ASR system을 활용하여 만든 것임을 확인.
원시 데이터셋에 상당량의 저품질 전사본이 포함되어 있음을 확인
전사본 품질을 향상시키기 위한 여러 자동 필터링 방법을 개발했습니다.
- 모든 문자가 대문자이거나 소문자인 경우 제거
- 발화된 언어와 전사본의 언어가 일치하는지 확인 후, 불일치하는 경우 제거
- 오디오를 30초 단위로 segment로 나누어, 해당 시간 segment내에서 발생하는 script와 쌍을 이룸.
오디오 파일은 30초 길이의 세그먼트로 나누어 해당 시간 세그먼트 내에서 발생하는 전사본의 일부분과 짝을 이룹니다.
* 역 텍스트 정규화 ( inverse text normalization ) ?
ITN(Inverse Text Normalization)은 음성을 글로 변환하는 프로세스.
예를 들어, 음성 "four"는 서면 형식 "4"로 변환됨.
텍스트 출력에 적용되는 ITN 규칙
| 인식된 음성표시 | 텍스트 |
| that will cost nine hundred dollars | That will cost $900. |
| my phone number is one eight hundred, four five six, eight nine ten | My phone number is 1-800-456-8910. |
| the time is six forty five p m | The time is 6:45 PM. |
| I live on thirty five lexington avenue | I live on 35 Lexington Ave. |
| the answer is six point five | The answer is 6.5. |
| send it to support at help dot com | Send it to support@help.com. |
2.2. 모델
- 모델 : Transformer Encoder-Decoder 구조 채택.
- 모든 오디오 데이터는 16,000 Hz로 재샘플링되며, 10밀리초 간격으로 25밀리초 윈도우에서 80채널 로그-크기 Mel 스펙트로그램 표현이 계산됨.
- Feature 정규화 : -1 ~ 1 사이로 scaling 하고, 학습 데이터셋에서 평균은 0으로 맞춤.
- 폭이 3인 2개 Convolution layer(2번째 Conv의 stride=2) + GELU Act.
- Sinusoidal Positional Encoding
- Transformer Encoder Block
- Pre-activation Residual Block
- 최종 층에 Normalization 적용
- Transformer Decoder Block
- 학습된 위치 임베딩과 input-output token representation을 공유한다.
- 인코더와 디코더는 동일한 폭, 동일한 수의 transformer block을 갖는다.
- GPT-2의 BPE text tokenizer 사용
- 단, GPT-2에서 사용한 BPE는 영어에만 맞춰져 있음.
- 따라서, 다중언어 모델의 어휘를 재조정하기는 하나, 크기는 동일하게 유지.

2.3. 멀티태스크 형식
음성 인식 시스템은 단순히 text prediction 말고도, 음성 활동 감지, 화자 분할, 역 텍스트 정규화와 같은 다양한 task들을 포함하는데, 각각은 개별적으로 처리하면 비교적 복잡한 시스템을 구성하게 된다.
따라서, 우리는 복잡함을 줄이기 위해 단일 모델이 전체 음성 처리 파이프라인을 수행하도록 한다.
모든 task와 conditioning information을 decoder 의 Input 에 sequence 정보로 제공한다.
여기서 사용하는 디코더는 오디오 조건부 언어모델이기 때문에, 이전 텍스트 맥락에 조건을 두도록 훈련하여 더 긴 범위의 텍스트 맥락을 사용하여 모호한 오디오를 해결하도록 학습한다.
- whisper는 training 데이터가 30ms 단위로 잘려있
구체적으로, 일정 확률로 현재 오디오 segment 이전의 transcript text를 디코더의 context에 추가한다.
+ 예측의 시작을 나타내는 토큰 추가.
- * Decoder 훈련에 사용되는 input token 종류
- Text token
- special token
- < no speech >
- < transcribe >
- < translate >
- < start of transcription >
- < no timestamps >
- < end of transcript > - timestamp token
- Timestamp 예측의 경우, 현재 오디오 세그먼트에 대한 상대적인 시간을 예측.
이때, 모델의 기본 시간 해상도와 같은 20ms 단위로 시간을 양자화 한다. 그리고 각 시간에 대해 어휘에 추가
2.4 학습 세팅
Whisper의 확장 특성을 확인하기 위해 다양한 크기의 모델을 훈련 해 봄.
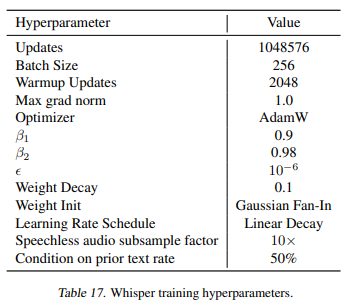
Epoch : few..?
데이터 증강이나 정규화를 사용하지 않고 대규모 데이터셋의 다양성에 의존하여 일반화와 robustness 강화.
- 모델이 화자의 이름을 잘못 전사하는 경향이 있음을 확인함.
이는 학습 데이터에 많은 화자의 이름들이 있어 예측하려고 하지만, 30초 오디오 내용만으로는 추론하기 여럽기 때문. 따라서, 화자 주석이 포함되지 않은 transcription data의 하위 집합에서 간단히 파인튜닝하여 이러한 양상을 제거함.
3. 실험
3.1 Zero-shot 평가
특정 도메인 상과없이 모델이 광범위하게 잘 일반화 되었는지 평가하기 위해, 기존의 음성 처리 데이터셋에 광범위하게 재사용 함. 각 데이터셋들의 훈련데이터셋은 사용하지 않고, zero-shot 설정에서 모델 평가.
3.2 평가 방법
- WER (Word Error Rate) : 문자열 편집 거리 기반 (사소한 오류에도 민감한 편)
이는 인간이 정확하다고 판단할 전사도 사소한 차이의 오류로 인해 높은 값을 가질 수 있음을 주의하자.
특히나 Whisper는 특정 데이터셋의 전사 형식을 본 적이 없기 때문에, 더욱 심각함.
이 문제를 완화하기 위해, WER 계산 전에 텍스트를 광범위하게 표준화 하여 비의미적 차이로 인한 페널티를 최소한으로 함. (인간이 수동 검사)

3.3 영어 음성 인식
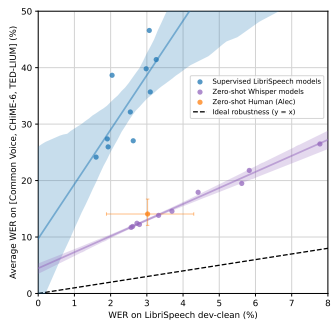
DataSet : LibriSpeech
- 보라색 : Whisper model
- 주황생 : 인간의 평가
- 파란색 : 다른 모델
평가 데이터셋의 분포에 대한 정보가 없이 평가 데이터셋을 받아들이는 것은 인간이나 Whisper나 동일하다.
하지만, 다른 모델들 같은 경우에는 학습 데이터로 분포에 대한 인지가 있는 상태에서 평가 데이터를 받아들이기 때문에 인간의 성능을 뛰어넘는 WER 값을 낼 수 있다.
즉, Whisper는 인간의 성능과 가장 유사한 모델이다.
다시 말하자면, 다른 모델들을 굳이 과대평가할 필요가 없다.
(인간의 성능을 내는 것 만으로도 충분하다)
-> 다양한 데이터셋에서 모델을 평가한 결과
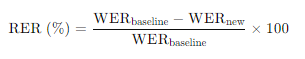
[Relative Error Rate]
wav2vec 2.0에 비해 Whisper 모델의 error가 얼마나 낮아졌는지 확인
baseline : Wav2vec 2.0
new : Whisper
3.4. 다중 언어 음성 인식
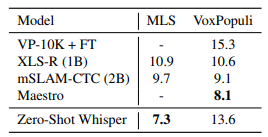
- MLS (Multilingual Librispeech)데이터에서 Whisper는 Zero-shot 설정에서 좋은 결과를 보인다. (텍스트 정규화를 했으므로, 정확한 비교가 아니라고 주장할 수도 있다.)
- 하지만, VoxPopuli 데이터에서는 점수가 낮음
-> 해당 데이터셋은 상당히 많은 지도학습 데이터를 가지고 있어서, fine-tuning에 유리하기 때문이라고 추정. - 위 데이터셋은 15개의 언어로 한정되어 있지만, Whisper는 75개 언어에 대한 ASR data를 가지고 있다.
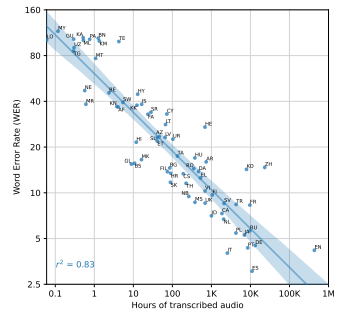
: 언어당 훈련 데이터와 WER의 관계
예상보다 성능이 저조한 가장 큰 예외는 히브리어(HE), 텔루구어(TE), 중국어(ZH), 한국어(KO)와 같은 고유한 스크립트를 가진 언어들이다.
이는 가장 많은 부분을 차지하는 (인도-유럽)과 멀리 떨어진 곳들이다.
- 언어적 거리 차이로 인한 전이 부족, BPE 토크나이저가 안 맞는 문제 등이 이유가 될 수 있다.
3.5. 번역
- 사용한 데이터 : CoVoST2의 X→en 서브셋(861시간)
X : 영어가 아닌 언어
제로샷 상태에서 29.1 BLEU 달성.
점수가 좋은 이유는, 이미 Whisper 모델의 학습 데이터에 68,000시간의 X→en 데이터가 있었기 때문.
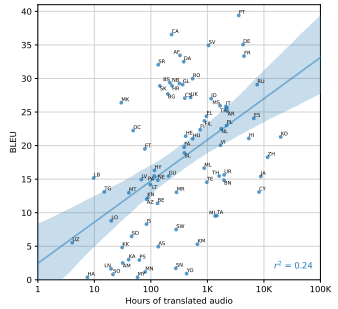
다양한 언어에서 평가하기 위해 Fleurs 데이터셋 사용.
-> 언어당 번역 훈련 데이터 양과 Fleurs에서의 zero-shot BLEU 점수간의 상관관계 (제곱상관계수)
데이터가 많을수록 좋아지는 경향은 있으나, 음성인식보다는 성능이 낮음
이는 노이즈가 많은 훈련데이터 때문일 것.
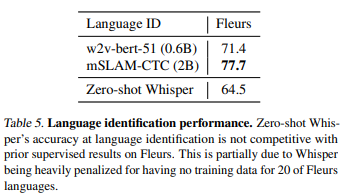
3.6. 언어 식별
언어 식별을 평가하기 위해 Fleurs 데이터셋(Conneau et al., 2022)을 사용
3.7. 추가 노이즈에 대한 견고성
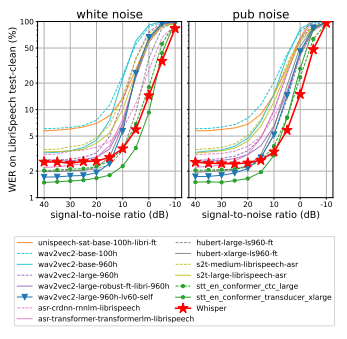
LibriSpeech 백색 소음 또는 술집 소음을 오디오에 추가하여 WER 평가.
Whisper의 노이즈에 대한 견고성을 보여주며, 특히 술집과 같은 더 자연스러운 분포 변화에서 뛰어난 성능을 발휘함.
3.8. 긴 형식 전사
Whisper 모델은 30초 오디오 청크로 훈련되며, 한 번에 더 긴 오디오 입력을 처리할 수 없다. 이는 실제 응용에 불리함.
따라서, 오디오의 30초 세그먼트를 연속적으로 전사하고 모델이 예측한 타임스탬프에 따라 윈도우를 이동시켜 긴 오디오의 버퍼링된 전사를 수행하는 전략을 개발.
긴 오디오를 신뢰성 있게 전사하려면 Beam Search 및 Temperature 스케줄링이 모델 예측의 반복성과 로그 확률에 기반하여 중요하다는 것을 관찰.
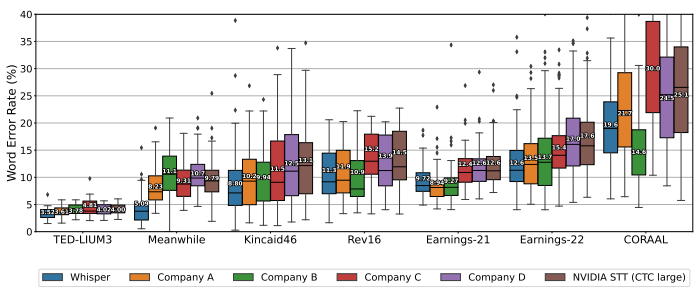
- 다양한 길이와 녹음 조건을 가진 7개의 데이터셋에서 긴 형식 전사 성능을 평가.
- 오픈 소스 모델과 4개의 상업 ASR 서비스와 성능을 비교.
결과적으로는 Whisper가 대부분의 데이터셋에서 나은 성능을 보임.
특히 uncommon words가 많은 Meanwhile 데이터셋에서 뛰어난 성능을 보였음을 보여주었지만, 이는 공개 데이터셋 중 일부가 Whisper 모델에 훈련되었을 가능성이 있어 정확한 판단이 어렵다.
3.9. 인간 성능과의 비교
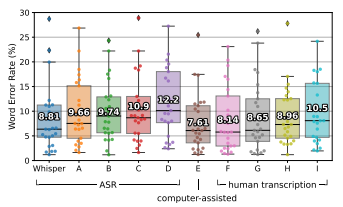
Whisper의 영어 ASR 성능이 완벽하지는 않지만 인간 수준의 정확도에 매우 가까움
References
- Whisper paper
- Whisper Review