matplotlib를 사용해서 그래프를 만들어보자.
import matplotlib.pyplot as plt
plt.plot([100,20,30,40])
plt.show() #matplotlib.pyplot 모듈의 show() 함수는 그래프를 나타내도록 함. (없어도 그래프가 나오긴 한다.)

위 문장에서처럼 리스트가 한 개인 경우, 리스트 [10,20,30,40]은 y값으로 인식된다.
x값은 자동으로 [0,1,2,3]을 만들어낸다.
다음으로는 리스트가 2개인 경우를 알아보자.
plt.plot([x값(들)], [y값(들)], x, y 값 인자에 대해 선의 색상과 형태를 지정하는 포맷 문자열 (Format string))
plt.plot([1, 2, 3, 4], [1, 4, 9, 16], 'ro')
plt.show()

첫 번째 리스트 [1,2,3,4]는 x값, 두 번째 리스트 [1,4,9,16]은 y값을 나타내고
'ro'에서 r은 red, o는 원형 모양으로 표시하라는 뜻이다.
이와같이 포맷문자열 설정은 다양해질 수 있다.



위의 조합으로 다양한 색과 무늬의 그래프를 만들 수 있다.
다음으로는 x와 y값의 범위를 지정하는 방법을 알아보자.
matplotlib.pyplot 모듈의
axis() 함수를 이용해서 축의 범위 [xmin, xmax, ymin, ymax]를 지정
plt.plot([1, 2, 3, 4], [1, 4, 9, 16], 'ro')
plt.axis([0, 5, 0, 50])
plt.show()

위에서 그려본 그래프와 x, y값은 변하지 않았지만, plt.axis([0, 5, 0, 50]) 을 통해서 x값의 범위와 y값의 범위를 지정해 주었다.
위 그래프와 차이점을 찾아보자면, x값이 1부터 4까지 밖에 없어도, x값의 범위를 0부터 5까지 지정해주었기 때문에 x축의 시작이 0이고 끝나는 점이 5가 된다.
만약 x값의 min,max범위가 x값의 리스트 범위를 포함하지 못한다면, 범위를 벗어난 리스트의 값들은 나타나지 않게 된다.
이는 y값도 마찬가지이다.
다음으로는 여러 개의 그래프를 그리는 방법을 배워보자.
plt.plot(x, y1, 'r--', x, y2, 'bs', x, y3, 'g^') 그래프를 3개 그려보기
import matplotlib.pyplot as plt
import numpy as np
x = np.arange(0., 5., 0.2) # 200ms 간격으로 균일하게 샘플된 시간
plt.plot(x, x, 'r--', x, x**2, 'bs', x, x**3, 'g^') plt.show() # 빨간 대쉬, 파란 사각형, 녹색 삼각형

그럼 제 1장 예제를 분석해보자.
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(list(graph_data.index), graph_data["PC-A"], label='PC-A')
plt.plot(list(graph_data.index), graph_data["PC-B"], label='PC-B')
plt.plot(list(graph_data.index), graph_data["PC-C"], label='PC-C')
plt.plot(list(graph_data.index), graph_data["PC-D"], label='PC-D')
plt.plot(list(graph_data.index), graph_data["PC-E"], label='PC-E')
plt.legend()

위 그래프를 이해하기 위해서는, 이전의 데이터 상황을 알아야 한다.
바로 이전의 문장을 보자.

이처럼 join_data의 행과 열을 지정하여 연도별, 상품별 매출의 총합을 구해둔 것을 graph_data라고 새롭게 명명하였다.
그럼 다시 matplotlib 모듈의 plot 문장을 읽어보자.
import matplotlib.pyplot as plt
%matplotlib inline
맨 위 두 문장은 matplotlibd을 임포트하고 주피터 노트북에 표시하기 위한 코드이다.
그래프를 그리는 문장은 아래 5줄이 그 역할을 한다.
plt.plot(list(graph_data.index), graph_data["PC-A"], label='PC-A')
plt.plot(list(graph_data.index), graph_data["PC-B"], label='PC-B')
plt.plot(list(graph_data.index), graph_data["PC-C"], label='PC-C')
plt.plot(list(graph_data.index), graph_data["PC-D"], label='PC-D')
plt.plot(list(graph_data.index), graph_data["PC-E"], label='PC-E')
첫번째 문장만 확인하면 이후는 동일하다. plt.plot( list(graph_data.index), graph_data["PC-A"], label='PC-A')
여기서 x값은 graph_data의 인덱스를 리스트형태로 놓은 즉, 연도를 뜻하고 y값은 graph_data에서 PC-A열을 의미한다.
뒤에 붙은 label은 그래프 선에 이름을 PC-A로 붙이는 것을 의미한다.
추가적으로 label의 위치도 정할 수도 있는데,
plt.legend()
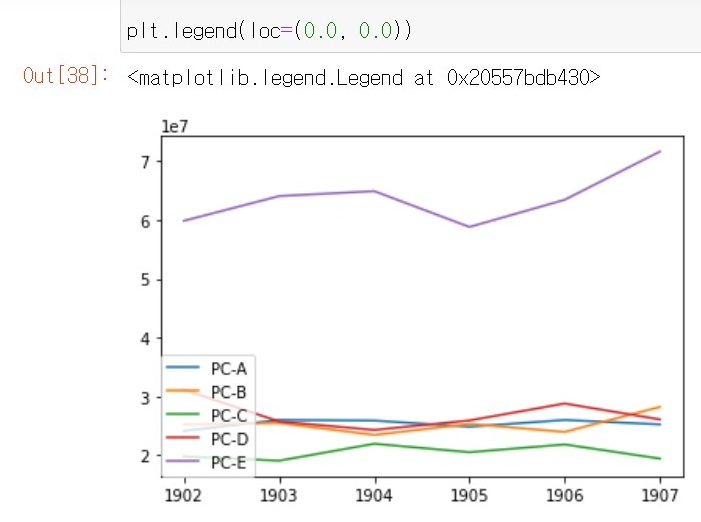
legend()함수의 loc파라미터를 이용해서 범례가 표시될 위치를 선정할 수 있다.
예를 들어, 위와 똑같은 그래프에서 plt.legeend(loc=(0.0, 0.0)) 을 바꾸어 입력하면, 아래와 같이 범례가 (0,0) 지점에 위치해 있는 것을 볼 수 있다.
'Phython > pandas' 카테고리의 다른 글
| loc(), iloc() (0) | 2023.06.20 |
|---|---|
| groupby(), groups.func() (0) | 2023.06.12 |
| 데이터 프레임 합치기 concat(), merge(), join (0) | 2023.06.06 |

